Today’s petascale computers can perform on the order of a quadrillion operations – 1015 – per second. To enable exascale machines, which will be a thousand times faster, computer scientists must conquer many software obstacles, developing elaborate programs that maximize the added power. Exascale architectures are expected to have complex memory systems, networks and accelerator technologies.
Applications that run on high-performance computing (HPC) systems also are growing more convoluted, and performance often depends on the input data. Changing an application to make the best use of a machine can require painstaking modifications.
At the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory in California, computer scientist Todd Gamblin works on automating the fine-tuning of applications for HPC. His research, he says, “explores ways to build machine-learning techniques that predict the causes of performance problems and how to improve them.”
Statistical models, Gamblin says, can predict a program’s performance even when the input data change. But those modeling techniques must be easy to use if application developers and HPC experts are to adopt them. The payoff: faster and easier code optimization on even the most advanced computers.
Technology to do this automatically, though, must factor in many elements, including how an application uses different parts of the processor chip, memory and network – behavior that can differ within the same computer. “A program spread over a giant machine may behave differently in one core than another, and we need to understand why,” Gamblin says. For instance, what part of a program “depends on application physics? What part is completely dependent on the hardware?”
To make these algorithms run fast, though, Scovazzi will need exascale computing.
To automate this technology, Gamblin starts with what is already known. “We’ve optimized programs for some time, and we have a good idea of what causes some performance problems,” he says. “We’ll start by building a prototype that predicts what we know already, and we’ll apply that to discover new performance effects in uncharted territory.”
Although “big data” is one of today’s most-used buzz phrases, some parts of the concept are not new, says Florin Rusu, assistant professor in the school of engineering at the University of California, Merced. “I’m a database person, and we have been managing large amounts of data for years,” he says. “So instead of big data, the real challenge is integrating machine learning into databases.”
Rusu hopes to do that with an interactive exploration of data. It’s needed, he says, because “you may have lots of data being analyzed in a program that runs for a long time, and you’re not even sure what you’re looking for. In interactive exploration of the data, we design methods that allow us to verify hypotheses much faster.”
He envisions two approaches. One uses approximations, or simply running the programs with a small part of the data to see what happens, then extrapolating that to the entire data set. Another method also could simultaneously run multiple programs, each testing a different hypothesis. Today’s computers provide enough parallelism to do this, breaking problems into pieces running on multiple processors, but tapping so much data from memory creates a bottleneck.
“So we want move the data as little as possible,” Rusu says. “You want to move it once, and do all of the computations that you can.”
Much of the time is spent on data loading, which maps the raw data to the format an application requires on a specific computer system. “The data mapping can take much longer than the computation,” Rusu says. He hopes to remove this slowdown with in situ processing – that is, using primary computing resources – and he has done processing on raw data at the same speed as loaded data.
On the other hand, a computer could do some data loading when it has time while making sure not to interfere with processing. “One of my goals is to push resource utilization to the maximum,” Rusu says.
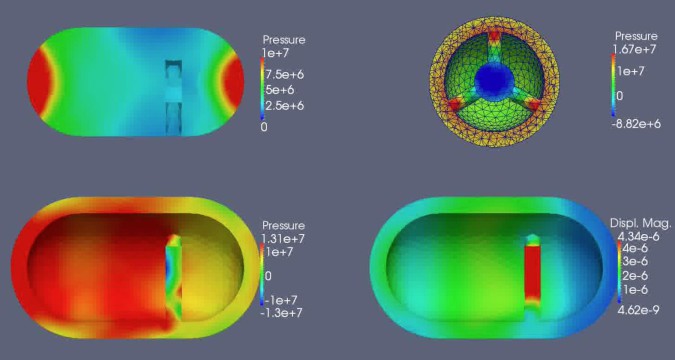
Exascale computing could prove especially useful for multiphysics problems – simulations involving coexisting physical processes. Explains Guglielmo Scovazzi, associate professor in the department of civil and environmental engineering at Duke University in Durham, North Carolina: “Some of the challenges can be associated with the geometrical complexity that arises in high-resolution computations. In fact, building the computational grids required in simulations can create very complex scenarios, especially when you want to work at scale.”
In particular, Scovazzi studies fluid-solid interaction problems. For such problems, some areas of the domain being modeled need a finer computational grid than others.
Meanwhile, the time scales often can vary between different materials. For example, when modeling a wing moving in a fluid, like a spinning wind turbine blade, the interface of the two physics – the boundary layer where the fluid impinges on the wing – needs the finest mesh, and the fluid probably must be modeled on a shorter time scale than the structure.
To make these algorithms run fast, though, Scovazzi will need exascale computing, at least for high-fidelity simulations of very complex shapes.
To improve these models, Scovazzi works on embedded interface algorithms for computing fluid/structure interaction on unstructured grids. If exascale computations use a geometry-conforming grid of many billion elements, there is statistical evidence that millions of grid cells will have bad shapes and overall poor computational performance. A better strategy is to release the requirement that grids must conform to geometric shapes and allow grids for the solid and the fluid to overlap and intersect.
As Scovazzi says, “This poses a whole new class of problems that we need to conquer and master to deliver exascale-ready algorithms that are robust, accurate and efficient.” Lots of work lies ahead for next-generation computer scientists.
The COVID-19 response demonstrated how computational biology could enhance public health research. Though the pandemic… Read More
Diamonds aren’t just beautiful sparkly rocks or a girl’s best friend; they’re also the hardest… Read More
More than a century ago, scientists pondered how evolution might be driven by mutations caused… Read More
Scientists, industries and policymakers have been working for years to find energy storage technologies that… Read More
The human brain contains a vast expanse of unmapped territory. An adult brain measures only… Read More
Computer scientists are democratizing artificial intelligence, devising a way to enable virtually anyone to train… Read More
{kind=link}