Next year, the Jaguar supercomputer at Oak Ridge National Laboratory (ORNL) will get a new name: Titan. The move is more than cosmetic. It reflects the growing prominence of graphics processing units, or GPUs, in supercomputing.
Until recently, the workhorse central processing unit, better known as the CPU, has been the computational mainstay in systems ranging from desktops to the most advanced, room-filling Cray and IBM supercomputers. Working together in massively parallel systems, CPUs have carried out the program instructions behind ever more detailed and refined scientific simulations.
But GPUs, best known as the pixel-herding backbones of gaming systems, have started to co-inhabit supercomputers, due in part to the increasing importance of scientific imaging. Other GPU advantages – the massively parallel way they work together and their energy thriftiness – could address looming high-performance computing logjams.
“A CPU is essentially designed to make Windows, Word or PowerPoint run faster,” says Sumit Gupta, who manages Tesla, the current line of high-performance GPUs made by NVIDIA, the company that invented graphics processing units in the late 1990s. “That’s a sequential job. The analogy I have for that is delivering pizzas on one big truck that drives from home to home sequentially or serially.”
But the serial solution doesn’t fit certain problems. “A scientific simulation is an inherently parallel task. Let’s say I’m trying to forecast the weather. I need to figure out moisture, the impact of the wind and the temperature. I’m trying to simulate the activity of millions of particles in the atmosphere at the same time.”
Enter parallel processing. “It’s like hiring many motorcyclists to make separate pizza deliveries to each home at the same time. Fundamentally, our graphics processing units have always operated in parallel because the gaming world works in parallel as it manages how pixels are laid out.”
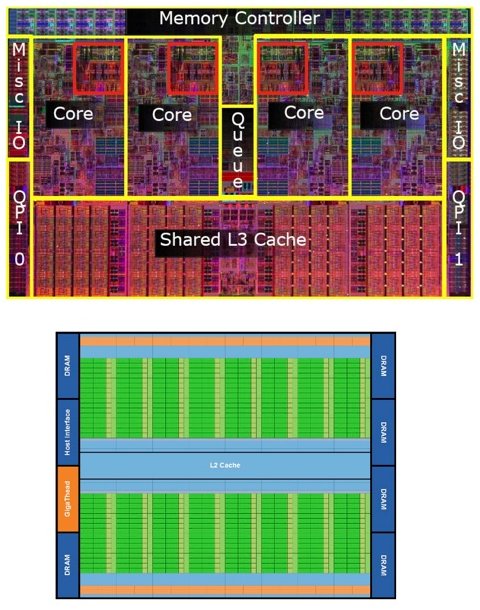
Gupta says Intel’s new Core i5 is a typical modern CPU composed of 774 million transistors. It devotes about 40 percent of its area to memory caches that can get lots of data out the door rapidly. The Core i5 also contains four separate computing units called cores; some other CPUs contain as many as eight. Each of those cores can be used for a limited form of parallel processing but has nothing approaching the capability of a GPU, also known as a graphics accelerator for its ability to speed up image rendering.
Only a small part of a CPU is devoted to performing direct calculation (top, highlighted in red), compared with a GPU. A schematic of an NVIDIA GPU’s architecture (bottom) shows multiple streaming processors. Each processor has 32 cores, each of which can execute one floating-point operation per clock instruction. Images courtesy of Intel and NVIDIA.
For example, a late-model NVIDIA GPU, the Tesla M2090, contains about 3 billion transistors and 512 much smaller cores. It also has sets of data-sharing caches, but most of its real estate is devoted to using its multicores for massively parallel computing.
Steve Scott, the company’s new chief technology officer for GPU computing, formerly held the chief technology officer job at Cray Inc., which has just begun shipping its first supercomputers that use both NVIDIA GPUs and AMD CPUs. Each core of a CPU “is really designed to run a single thread of computation quickly” he says, and CPUs were first built in an era when all programming was serial.
But the computing world has gone parallel, Scott says. “And that’s not about running one thing as fast as possible. It’s about running lots and lots of parallel threads of computation.”
CPUs in a 1990s-era Cray supercomputer also could interact in parallel using what’s called vector processing. Each core handled a number of differing pieces of data at once in a single instruction.
That “is just one of the components we’re exploiting today with the GPU,” Scott says. “The GPU is exploiting other levels of parallelism on top of that, all inside the same chip.”
The energy demands of high-end computing are apparent at places like ORNL’s Leadership Computing Facility, where three Cray supercomputers share one large space. “Our machine room is rated for almost 20 megawatts of power, but we can’t do much more,” says Bronson Messer, who heads Oak Ridge’s Center for Applications Readiness. “We play all kinds of tricks to keep that load down.”
NVIDIA says Oak Ridge’s Jaguar supercomputer is an example of CPU power hunger. According to company benchmark figures, the 224,000 cores in Jaguar’s CPUs – six per processor – can sustain performance at 1.76 petaflops, meaning a million billion floating-point operations a second. But it costs Oak Ridge 7 megawatts of power when Jaguar computes at that rate. By comparison, Tianhe 1-A, a new all-GPU Chinese supercomputer, requires just 4 megawatts to operate at a higher 2.6 petaflops.
‘We have several applications that show dramatic performance improvements running on GPUs.’
Messer is part of the management team that is upgrading Jaguar with a combination of GPUs and CPUs, with NVIDIA and Cray engineers participating in the evaluations. By the time Jaguar becomes Titan, it will turn out 10 to 20 peak petaflops. “Titan is likely the way that things will go,” Messer says. “We can’t afford to go to much higher power densities. That’s why people are investigating GPUs.”
The idea is to have CPUs and GPUs working together, perhaps someday integrated into the same chip. Researchers already are finding that in many cases GPUs can dramatically accelerate solving many kinds of high-end computing problems.
“It’s like a car with a turbo engine in it,” NVIDIA’s Gupta explains. “The GPU is the turbo. Without it the car runs just fine. But when you switch on the turbo you get that speed boost.”
Also at Oak Ridge, a National Science Foundation-funded project in experimental computing known as Keeneland is evaluating the performance of what computer scientists term heterogeneous combinations of GPUs and CPUs. Keeneland’s initial system is a cluster of Hewlett Packard nodes loaded with 360 NVIDIA GPUs and 240 Intel CPUs. In 2012 it will expand to about 2.5 times its current size.
Keeneland is a collaboration of the Georgia Institute of Technology, the National Institute for Computational Sciences at the University of Tennessee-Knoxville and ORNL. The system is offering 200 users the chance to evaluate whether heterogeneity can better solve challenging computational problems in fields ranging from molecular dynamics to astrophysics to data-mining.
“We have several applications that show dramatic performance improvements running on GPUs,” says Jeffrey Vetter, a Georgia Tech computer science professor with a joint appointment at Oak Ridge who also is Keeneland’s principal investigator and project director. “For example, a prominent bimolecular simulation application named AMBER performs as well on a cluster of eight GPUs as 200 CPUs.”
NVIDIA also reports comparable speedups on scores of other experimental CPU-GPU clusters on four continents.
One example is an imaging system that smooths out the jerky video from high-flying robotic drone aircraft. “GPUs can immediately display vital images of the surrounding terrain, while CPUs take six hours to process one hour of video,” a company case study says.
A University of Illinois simulation of Tamiflu’s effectiveness in treating mutating forms of the H1N1 virus took more than a month on CPUs alone, compared with a little more than an hour when GPUs were added. And a French research lab found that GPU acceleration can “virtually still a beating heart,” potentially enabling “surgeons to treat patients by guiding robotic arms that predict and adjust for movement,” reports NVIDIA, which dominates the market for GPUs in high-performance computing.
The company has been awarded one of four U.S. Defense Advanced Research Projects Agency-funded projects focusing on the groundbreaking technical improvements that could upgrade supercomputing to the next performance level – the exascale. That’s a billion billion operations per second, a thousand times that of the petascale.
NVIDIA has already begun its own prototype exascale-level GPU design project, called Echelon, with a target date of about 2018 for a working device.
An exascale supercomputer might attack such currently unsolvable problems as understanding nuclear fusion at a deep level, creating Earth-encompassing weather models that would include local variations or modeling an internal combustion engine with high fidelity. “Whether it’s chemistry, biology, physics, geology or climate, the scientists have bigger problems that they want to solve,” NVIDIA’s Scott says.
Exascale supercomputers may contain more than 100 million processor cores, “all working in parallel, all having to synchronize and communicate with each other,” he predicts. “So we would have to find a billion completely independent tasks to do every clock tick.” That would require really big problems, and finding enough parallelism at every possible level.
Prognosticators say exascale processors also would have to operate with 100 times the energy efficiency of today’s. And since moving information around such monster machines would cost more than computing on them, all that data would have to be localized near where it is processed – and acted on multiple times.
Another big hurdle is software. Today’s NVIDIA chips enlist so-called CUDA architecture, allowing familiar CPU-friendly programming languages such as C, C++, or FORTRAN to also work on GPUs. But exascale software would be so complex, Scott says, that there’s “ a grand challenge to hide that complexity from the programmers so they don’t get buried in it.”
It all sounds like a tall order in 2011, with even the kinds of processors under review. “I’m not saying that an exascale machine at the end of this decade is going to be made out of GPUs,” Oak Ridge’s Messer says. “But it’s going to be massively multicore. And it’s probably going to have accelerators” like GPUs.
The COVID-19 response demonstrated how computational biology could enhance public health research. Though the pandemic… Read More
Diamonds aren’t just beautiful sparkly rocks or a girl’s best friend; they’re also the hardest… Read More
More than a century ago, scientists pondered how evolution might be driven by mutations caused… Read More
Scientists, industries and policymakers have been working for years to find energy storage technologies that… Read More
The human brain contains a vast expanse of unmapped territory. An adult brain measures only… Read More
Computer scientists are democratizing artificial intelligence, devising a way to enable virtually anyone to train… Read More
{kind=link}