As high-performance computers bring more power to programmers, communication often limits an operation’s overall speed.
Even a seemingly simple computing challenge like building a histogram can reveal the need for new approaches to orchestrating parallel interactions between hardware and software. That’s because datasets too large to fit on a single processor’s memory must be spread over multiple processors.
“Randomly reading or writing a distributed data structure like a histogram can be very expensive on large-scale parallel machines,” says Katherine Yelick, professor in the computer science division at the University of California at Berkeley and NERSC (National Energy Research Scientific Computing Center) division director at Lawrence Berkeley National Laboratory.
Other factors, such as the increasing number of processor cores per chip and the difficulty of random-access communication across all of a machine’s cores, further push the limits of today’s parallel computing approaches. Such challenges stimulated the development of Unified Parallel C, better known simply as the UPC language.
Message Passing Interface (MPI) has long been the primary way processors communicate in high-performance computers (HPC), “but people are finding some limitations in it,” says Paul H. Hargrove of the HPC research department at Lawrence Berkeley National Laboratory.
For instance, if data must be used by multiple processors, MPI often makes copies of that data. In the histogram example, MPI might replicate and later combine instances of the histogram. Even when using nearest-neighbor communication, MPI often replicates some of the data to reduce some forms of communication. As a result, MPI uses up some memory just for copies of data.
UPC tries to resolve some of MPI’s shortcomings, Hargrove says. In particular, UPC takes a new approach to communicating between processors. As a result, a range of experiments show UPC often outperforms MPI – usually by a large margin.
‘A program running on a remote processor doesn’t even know about the communication.’
MPI uses so-called two-sided message passing. When passing data between processors, a programmer must use a “send” and a “receive” command; one processor uses “send” to alert another that data are coming, and the target processor uses “receive” to say that it’s ready. The “send” provides the data destination, the length of the information being sent, and so on. An MPI “receive” requires matching information.
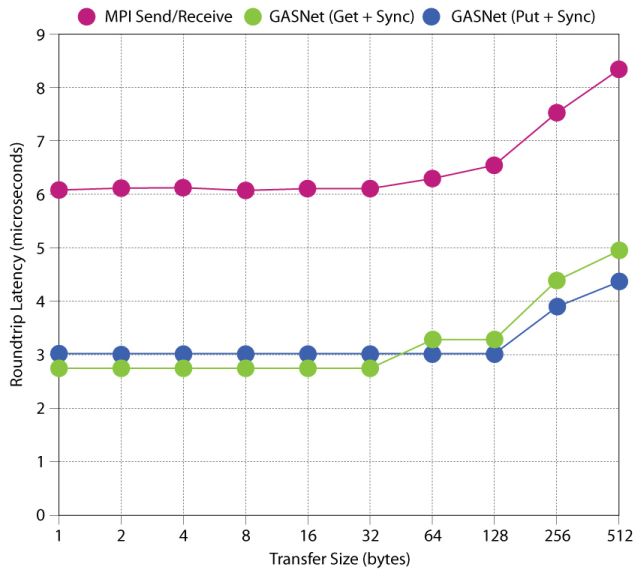
Most of the communication in today’s high-performance computers relies on the Message Passing Interface (MPI), which uses two-sided message passing. As shown in these data, MPI takes longer to move information than do approaches such as GASNet that use one-sided message passing.
For a random-access pattern, as in the histogram, it’s difficult to know when to “receive” data, because only the sending processor has information about where the data should go.
“There is a certain overhead associated with the processing,” Hargrove says. “You can’t move data for one MPI task until both sides of the communication have been processed.”
In contrast, UPC uses one-sided communication. Here, an operation called a “put” is like an MPI “send,” except a “put” doesn’t need to get matching information from a “receive.” Hargrove says that such a UPC operation might just say: “Write 200 bytes from this local address to that remote address,” or “fetch 300 bytes from this remote location and put it in this local spot.” As such, one-sided communication works with only one side knowing the communication is taking place.
“A program running on a remote processor doesn’t even know about the communication,” Hargrove says.
With UPC’s one-sided communication, Yelick and her colleagues could overlap communication and computation.
“Rather than waiting for all computation to complete, the communication starts as soon as some part of the data is ready to send,” she says. This can be done with MPI, but it works better in a one-sided model where communication overhead is lower. UPC makes it possible to send smaller messages efficiently and, therefore, start overlapping communication earlier. As Yelick says, “Underneath the covers of UPC, the runtime system picks up the data and puts it in the memory while computation continues.”
UPC is one of the Partitioned Global Address Space (PGAS) languages for large-scale parallel machines. These create an illusion of globally shared memory by using one-sided communication, regardless of the underlying hardware. Besides UPC, PGAS languages include Titanium, Co-Array Fortran, X10 and Chapel, as well as libraries like Global Arrays.
To see how UPC stacks up against MPI, Yelick and her colleagues turned to Parallel Benchmark FT, a tool developed by the Numerical Aerodynamic Simulation (NAS) Program at the NASA Ames Research Center. The benchmark uses forward and inverse Fast Fourier Transforms (FFTs) to solve a three-dimensional partial differential equation.
“This involves global transposes of the data set, which is typically the performance bottleneck,” Yelick says.
The team tested a number of computing platforms, most recently Intrepid, the Blue Gene/P at Argonne National Laboratory’s Leadership Computing Facility. The tests ran on 16,384 of Intrepid’s 163,840 cores.
The Berkeley UPC compiler suite consists of several pieces of software. First, UPC code gets converted to regular C. Then, a runtime library specific for UPC provides memory management and other capabilities. Next, GASNet, which stands for Global-Address Space Networking, connects the code to the network. This UPC compiler suite works with a range of architectures and operating systems.
UPC hit 1.93 teraflops (trillion floating-point operations) while running the benchmark program, compared to 1.37 teraflops for MPI – a 40 percent improvement. At times, UPC beat MPI by 66 percent.
The actual improvement, though, will vary under different circumstances. “The increase in speed attained with UPC is machine – and problem-specific,” explains Rajesh Nishtala, a graduate student in the Berkeley UPC group.
Yelick’s team seeks an even more important objective than showing UPC can outrun MPI. With the Berkeley UPC compiler suite, its goal is to make a high-performance UPC compiler, a program that converts code into a lower-level code for execution. The suite will be designed to work with large-scale multiprocessors, PC clusters and clusters of shared-memory multiprocessors.
Three pieces of software comprise the compiler suite, starting with GASNet (for Global-Address Space Networking). “This is our library that provides networking support,” Hargrove says. “It provides implementation over different kinds of hardware for one-sided communication, but not for any one language” – so it works with UPC, Titanium, Co-Array Fortran and other languages.
Above the GASNet level, the Berkeley group works on a UPC runtime library. “This provides language-specific runtime support, like UPC memory management,” Hargrove says. “It uses constructs specific to UPC, and it runs on top of GASNet.” This software provides capabilities of UPC that are not in ordinary C.
The Berkeley scientists also work on compilation. “UPC code can’t just go in a C compiler,” says Hargrove. “So we need source-to-source translators that take UPC code and translate that to regular C code with calls to the UPC runtime library.” So instead of writing a complete compiler, Yelick and her colleagues provide translation from UPC to C.
Yelick and her colleagues want their compiler to work on many machines. “If a language only runs on one machine,” Yelick says, “application scientists won’t put in the effort to use it.”
The compiler suite works with a range of operating systems, including Cray Unicos, Linux, Mac OS X, Microsoft Windows, Solaris and others. It also works on many types of processors, including those in the IBM Blue Gene/L and P, various Cray processors, Sun’s SPARC, x86 architectures and others – even the Cell processor used in the Sony Playstation 3. Plus, the Berkeley suite generates C code that works with many C compilers, including Cray C, GNU GC, HP C, IBM VisualAge C, Intel C and others.
Yelick and her colleagues also want the Berkeley UPC compiler suite to be user-friendly. “For a C programmer, UPC is very easy to pick up,” Yelick says. “There is just a small set of new constructs in the language.”
Not least, Yelick says, the compiler is a highly portable implementation that’s easy to set up. “The effort needed to get our UPC up and running is not much more than what it takes to get MPI up and running on the same architecture.”
Although Yelick and her colleagues stopped their benchmark tests on the Blue Gene/P at just a tenth of its processors, it’s not because of any fundamental limits on their software. They expect that GASNet and their UPC will work with many more cores, and they intend to test that. In addition, the Berkeley team hopes to try out higher scaling on other parallel machines, including the Cray XT. The results from such tests could show that this UPC can solve even bigger problems and work at high levels of parallelism on various machines.
Next-generation UPC advances also will go beyond testing to adding features. For example, even though UPC uses one-sided communication to speed up applications, the data used in specific situations can be held in widely separated locations, and getting to that data takes time.
“It seems from some of our work on performance tuning for multicore machines that the placement of data within the memory system is very important,” Yelick says. “We want to minimize movement between memory that is on-chip and off-chip.” To do this, Yelick wants to let the programmer manage the data locations.
“UPC can read or write any data, but some data are nearby and some are farther away,” she says, adding that “it would be very useful if you could manage the location of data in the memory hierarchy. That would be especially important for people writing the most highly optimized codes and libraries.” Future versions of Berkeley’s UPC code might provide that capability.
In addition, UPC could learn something from MPI. For example, MPI includes communicators – specific groups of processes that lets some programs be written more effectively with subsets of tasks. “UPC lacks (an) equivalent to communicators,” Hargrove says.
“Our UPC team will address that, and we are hoping that the UPC-language community will adopt something like communicators into the language.”
The COVID-19 response demonstrated how computational biology could enhance public health research. Though the pandemic… Read More
Diamonds aren’t just beautiful sparkly rocks or a girl’s best friend; they’re also the hardest… Read More
More than a century ago, scientists pondered how evolution might be driven by mutations caused… Read More
Scientists, industries and policymakers have been working for years to find energy storage technologies that… Read More
The human brain contains a vast expanse of unmapped territory. An adult brain measures only… Read More
Computer scientists are democratizing artificial intelligence, devising a way to enable virtually anyone to train… Read More
{kind=link}
{kind=link}