If bytes were pennies and you stacked them, they would go from Jupiter to the sun and back, by the time you reached one petabyte.
Given such a tower of data – an amount of information appearing in modern scientific computing with increasing frequency – the trick becomes moving it and moving it quickly. It can be done, but only with the right software.
Moving data depends on a sometimes-neglected aspect of computer systems known as input/output, or I/O. “We teach about computer architecture, starting with the processor,” says Wu Feng, associate professor in the departments of computer science and electrical and computer engineering at Virginia Tech in Blacksburg. “Then, we teach about the memory hierarchy, including caches and virtual memory. By the time we get to the end of a semester and have just a couple of classes left, I/O gets thrown into the mix as an afterthought.”
In large-scale, parallel-processing computers, though, every aspect of a system must be balanced to get top speed. Many of today’s systems stumble in the I/O realm, making it a bottleneck that can back up entire computations.
One of the first approaches to advanced parallel I/O came from Rob Ross, a computer scientist at Argonne National Laboratory (ANL). Ross led the development of the Parallel Virtual File System (PVFS). As Ross’s webpage puts it, he and colleagues have used PVFS to achieve something like pulling a few DVDs’ worth of data into your computer in a second. Nonetheless, I/O also must work far beyond a scientist’s desktop.
In many situations today, scientists rely on wide-area networks to send information to high-performance data centers, sometimes around the world. To make that possible – in a reasonable amount of time – Feng, Pavan Balaji (assistant computer scientist in ANL’s Mathematics and Computer Science Division and a fellow of the Computation Institute at the University of Chicago), and their colleagues developed ParaMEDIC (parallel metadata environment for distributed I/O and computing). Moreover, these researchers performed a biology experiment in which they dramatically improved the speed of I/O, even when moving data around the world.
One of many areas in need of improved I/O is biology, where giant genomic datasets are becoming the norm. Moreover, biologists often compare data across organisms. For example, the popular BLAST (basic local alignment search tool) software compares biological sequences, such as the strings of bases, or nucleotides, that make up DNA. The amount of data to search, meanwhile, keeps increasing. GenBank, the National Institutes of Health’s genetic sequence database, holds 86 billion or more bases. So as the data grow, BLAST must work faster to keep searches doable.
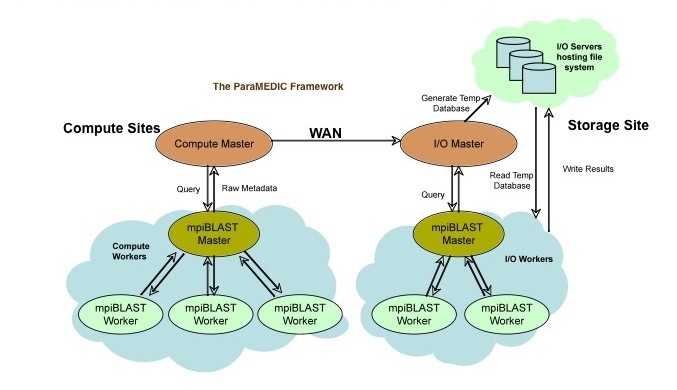
As shown here, ParaMEDIC decouples computing (left) and I/O (right). In this case, an mpiBLAST plug-in processes output to create metadata, which are orders of magnitude smaller than the raw data. ParaMEDIC then sends the metadata to a storage site (upper right) and runs mpiBLAST there to recreate the raw data. Image courtesy of Pavan Balaji.
In response, Feng and colleagues developed mpiBLAST, which uses distributed computer resources to boost performance by several orders of magnitude. For example, mpiBLAST sped up BLAST by 305 times using 128 processors. “How do you get more speed than workers?” Feng asks. “The answer comes from using the most appropriate mapping of a problem to the computer hardware and avoiding I/O.”
But even mpiBLAST alone cannot solve every biological-sequencing challenge. For instance, scientists at the Virginia Bioinformatics Institute at Virginia Tech wanted to look for missing genes in 567 microbial genomes. Using ParaMEDIC, Balaji, Feng and their colleagues took on that challenge, which required 2.63 times 1,014 sequence searches.
To perform those computations, the scientists assembled an aggregated supercomputer. It consisted of more than 12,000 cores spread across eight supercomputers in the United States, plus 500 terabytes (half a petabyte) of storage in Japan. “The bottleneck was a shared gigabit Ethernet that created a trans-Pacific link to Tokyo,” Feng says.
The biological computations generated 0.97 petabytes of data. If the researchers aggressively got 10 percent of the shared bandwidth across the Pacific, it would have taken three years just to deliver all the data to Tokyo. Balaji and Feng’s team, though, performed the computation for the missing genes, transmitted the data and recovered the information all in just 10 days. This application of ParaMEDIC won the Storage Challenge at SC07, the international supercomputing conference.
‘Our APIs can reduce I/O code by a factor of five or more.’
Instead of taking data generated by computation and simply pushing it into the output connection, ParaMEDIC turns the information into metadata. That is, the software adds another computation step to reduce the size of the data in application-specific ways. “If two people are talking in English, that makes lots of data,” Balaji explains. “But what if they share some kind of code that they both understand? Some code, which uses a lot less characters than English, could let them talk by exchanging a much smaller amount of data, and convert the code back to English when they are done.” Just as ParaMEDIC does, one person would translate a message into a code, transmit the code, and then the other person would translate it back to the original.
Balaji, Feng and their colleagues used such an approach with the missing microbial genes. So-called GenBank identifiers represent specific sequences. So instead of recording all of the nucleotides that make up a sequence, which is the output from mpiBLAST, ParaMEDIC can use the identifiers, or metadata, which can be three to four orders of magnitude smaller.
As a result, ParaMEDIC crunched the 0.97 petabytes of data into about 4 gigabytes – so little data that it could be stored on some iPod Nanos. Once that metadata reached Tokyo, another step in computation used the metadata to recreate the original 0.97 petabytes of information.
“It was a tradeoff,” Feng says. “We took a little more computation time to gain a giant reduction in the time needed to move the data.” In fact, recreating the data from metadata was much less computationally intensive than computing the original data, requiring only 128 compute nodes for the former and 12,000 for the latter.
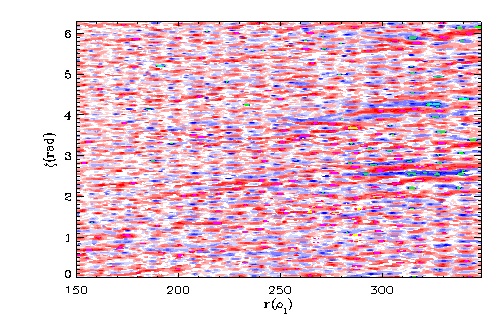
Using ADIOS with Gyrokinetic Toroidal Code produced datasets that could be used to simulate turbulence in a fusion reactor. These data ferret out size averages for radial turbulence eddies. Image courtesy of Scott Klasky.
Notably, Balaji and Feng’s team needed to understand mpiBLAST and GenBank to make ParaMEDIC work efficiently for this application. Likewise, other applications will require specific tweaks to the code. “We know what we need to do to generalize ParaMEDIC to make it possible to tailor it on a per-application basis with relatively low (computational) overhead,” Feng says.
Future applications could take ParaMEDIC into high-energy physics, earthquake predictions and other areas. Balaji also points out that ParaMEDIC could be used for remote visualization. “Imagine looking at a picture in a video,” he says. “The next picture is not much different. You could use the information about the first picture and then some code would generate the next image.”
Other scientists also are developing I/O improvements. In the summer of 2007, for example, a group of scientists came up with the Adaptable I/O System, or ADIOS. The team was made up of Jay Lofstead, a doctoral student at the Georgia Institute of Technology; Karsten Schwan, director of the Center for Experimental Research in Computer Systems at Georgia Tech; Chen Jin, a computer scientist at Oak Ridge National Laboratory (ORNL) in Tennessee; and Scott Klasky, a senior R&D scientist at ORNL.
Among other issues, ADIOS addresses one of the biggest problems in I/O: An approach can work well on one high-performance computing (HPC) resource on a certain number of processors, but when the resource runs on a higher processor count, I/O efficiency decreases. Moreover, the I/O scales differently on the different HPC resources.
With ADIOS, users can select the most efficient I/O method for their code with minimal code alterations or updates; they can store data in the desired file format because performance issues no longer drive those choices; and they can cope with the flood of output their codes produce because ADIOS helps efficiently identify and select certain data for analysis.
ADIOS makes it possible to independently select the I/O methods each grouping of data uses in an application so that end users can select those methods that exhibit the best performance based on both I/O patterns and the underlying hardware. ADIOS also allows users to change what is included in the output by editing an XML file and not changing the simple application programming interfaces (APIs) to output the data.
“In traditional I/O,” Klasky says, “you make calls to the write data, run your program, see the output, and then go back to change things if the output doesn’t look the way you want it to. With ADIOS, you can describe in an XML file how you want the output to look.” He adds: “Our APIs can reduce I/O code by a factor of five or more.”
Klasky describes ADIOS as “a combination of I/O componentization and new file formats.” This incorporation of I/O components allows toggling back and forth between various I/O methods – such as synchronous, asynchronous and real-time visualization. What’s more, ADIOS users can switch to different I/O implementations – for example, from ADIOS’s MPI (message-passing interface)-IO transport that Klasky’s team worked on to what Klasky calls a more efficient routine that Wei-Keng Liao from Northwestern University wrote or to an improved version of ORNL’s ADIOS MPI-IO routine.
ADIOS got some real-world experience running the Gyrokinetic Toroidal Code (GTC) to simulate turbulence in a fusion reactor. This simulation was developed at the Princeton Plasma Physics Laboratory and the University of California, Irvine. Running on Jaguar, ORNL’s Cray XT4 supercomputer, GTC using ADIOS writes out more than 60 terabytes a day and holds the I/O overhead to just 3 percent of the run time. The biggest challenges for the ADIOS team were running at scale and making sure that nothing went wrong with the I/O when the data had to be read back in for restarts. Componentizing the I/O allowed them to try several different I/O methods, such as MPI-IO and Posix, using their binary metadata-rich packed (BP) format, which is an indexed, log-based file format. Overall, this makes it easier to switch between I/O methods when there are problems.
To improve the I/O performance of a computer system, researchers need ways to determine how the data transmission really works. “The biggest challenge,” says John Shalf, group leader for system-driven computer architecture at Lawrence Berkeley National Laboratory (LBNL), “is setting up realistic I/O that reflects the user requirements. I/O benchmarking is often set up for idealized cases that you wouldn’t see in practice.”
Such problems grow even more complicated in supercomputer systems. “With supercomputers,” says Hongzhang Shan, computer scientist in the future technologies group at LBNL, “we really don’t have much experience in how to design I/O systems. We don’t always know how much parallelism we must support, or what new program interfaces we will need.”
In fact, today’s most commonly used program interfaces are a decade or so old. Moreover, I/O on a supercomputer system gets shared among many users. “So collecting I/O performance data tends to be more statistical,” Shalf says, “because it is nearly impossible to get dedicated access.”
To find a way to assess the real I/O of supercomputer systems, Shalf, Shan and Katie Antypas, a user consultant at the National Energy Research Scientific Computing Center, turned to the Interleaved or Random (IOR) benchmark, which was developed by the Scalable I/O Project at Lawrence Livermore National Laboratory. The software “basically creates a simplified set of I/O patterns that reflect ones that we see in real applications,” Shalf says. “The key thing is that you can specify your I/O patterns.”
For example, the user selects the transaction size of the data in a write statement and how many processors will be writing and where. Then a user can do head-to-head comparisons of various I/O systems and different programming interfaces.
Shalf, Shan, and Antypas applied IOR to many applications and found that the simulation accurately reflected I/O in the actual application. They plan to use IOR for selecting future supercomputers. This way, they can test the system before purchasing it and know just how the I/O will perform with specific applications.
So, much like supercomputer systems in general, I/O includes many components, from bandwidth and programming efficiency to interfaces and real-world assessments. Consequently, computer scientists can take a wide range of approaches to improving the simplicity of controlling I/O and the speed of data transmission – even when the pile of data could go into outer space and back.
The COVID-19 response demonstrated how computational biology could enhance public health research. Though the pandemic… Read More
Diamonds aren’t just beautiful sparkly rocks or a girl’s best friend; they’re also the hardest… Read More
More than a century ago, scientists pondered how evolution might be driven by mutations caused… Read More
Scientists, industries and policymakers have been working for years to find energy storage technologies that… Read More
The human brain contains a vast expanse of unmapped territory. An adult brain measures only… Read More
Computer scientists are democratizing artificial intelligence, devising a way to enable virtually anyone to train… Read More
{kind=link}
{kind=link}