Like falling dominos, the cascading processes that control how our body’s cells divide, grow and eventually die usually go as planned, moving smoothly to completion.
One misstep, however – like an out-of-place domino – and the chain breaks. Instead of advancing from beginning to end, the process repeats and cells proliferate into cancerous tumors.
A team from Department of Energy (DOE) laboratories, working with experimentalists at the National Cancer Institute’s Frederick National Laboratory for Cancer Research, is using massive computing power to decipher the misdirected cell protein connections that produce disease. With supercomputer time from the ASCR Leadership Computing Challenge (ALCC), part of DOE’s Advanced Scientific Computing Research program, they’ve developed methods that telescope computer models, linking multiple length scales via machine learning (ML) to rapidly focus on significant interactions.
The code runs thousands of low-resolution but fast simulations drawn from a mathematical sampling of myriad scenarios, uses ML to identify the most interesting outcomes and then passes them to a more precise model. ML further narrows those results and again passes them to the third, most demanding model, which simulates atoms interacting.
At each step, the program also sends feedback, from model to model, to improve future calculations.
The team’s framework, MuMMI (for multiscale machine-learned modeling infrastructure), won a best paper award at SC19, the 2019 international high-performing computing conference. That version connected only two scales, macro and micro. Using an ALCC grant of 600,000 node-hours on Summit, the IBM AC922 at Oak Ridge National Laboratory, the team added the third, atomistic scale and generalized the code for other applications.
“This is kind of our grand mission,” says Helgi Ingólfsson, a Lawrence Livermore National Laboratory (LLNL) staff scientist and co-investigator for the grant. Someday researchers won’t “set up a simulation. You are going to set up an environment where you want to sample” a range of parameter combinations. Then a MuMMI-like framework “will be sampling at different scales and you zoom in and out as needed.”
MuMMI, part of the DOE/cancer institute collaboration ADMIRRAL (AI-Driven Multiscale Investigation of Ras-Raf Activation Lifecycle), arose from the Cancer Moonshot program launched in 2016. The DOE researchers have targeted the Ras-Raf protein signaling pathway, where mutation-misshaped molecules are believed to cause nearly a third of all cancers diagnosed in the United States, including 95% of pancreatic, 45% of colorectal and 35% of lung cases.
‘We can do it tens of thousands of times without fail.’
Ras sits at the cell membrane and binds with proteins, particularly Raf, that are downstream in the pathway. Researchers are learning how membrane lipids (fatty acids) dictate protein orientation on the membrane and influence signaling.
The team, including other researchers from Argonne, Oak Ridge and Los Alamos national laboratories and from IBM, used its ALCC allocation from December 2020 through March 2021 to perform the largest-ever three-scale simulation of Ras-Raf membrane biology on Summit. In an SC21 paper, it reported the code occupied 98% of the machine’s 27,648 graphics processing units for more than 86% of the runtime and consumed more than 3.6 million GPU hours.
MuMMI is a framework that manages machine learning, interactions between scales, and the thousands of simulations that explore the parameter space. It links multiple independent tools, such as LLNL’s ddcMD modeling code, DynIm sampling tool, Maestro code automation and Flux job management tools, and others.
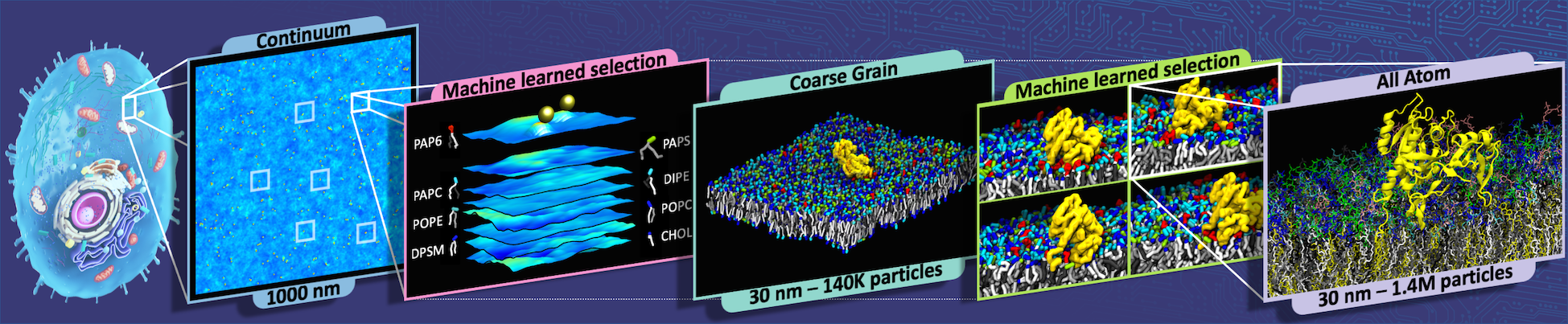
Models that portray Ras-Raf interactions on cell membranes at the level of atoms and molecules provide the best detail but are too computationally demanding to simulate long time spans or to run in great number. Because MuMMI bridges three scales – continuum, coarse-grained (CG) and atomistic – it can quickly simulate thousands of Ras-Raf interactions and pass only the most interesting ones to finest-scale model for detailed examination.
That third level is critical to understanding how signaling goes awry, Ingólfsson says. The CG model neglects changes to the proteins’ secondary structures – the shapes of local segments. Going to an atomistic scale illuminates those changes, which are then passed back to the CG model, improving the next simulation.
“The real magic,” Ingólfsson adds, is mapping simulations from lower-resolution models, with fewer degrees of freedom, to a higher-resolution models with more degrees of freedom and back again. “There was a lot of code optimization and error-tuning so we can do it tens of thousands of times without fail.”
ML is key to managing scales, steering explorations of Ras-Raf shapes, called conformations, to high-resolution models while limiting computational demand. MuMMI’s three-scale iteration also is composable – able to substitute ML methods as needed. For each pair of scales, continuum to CG and CG to atomistic, “there is a ML piece sitting between that tells you what to run or when,” Bhatia says. “If I change how my continuum scale was creating data, then likely my machine-learning methods will change. I want to have the system in a way that can easily absorb these changes.”
MuMMI works in situ – as the models run. The continuum code simulates cell membrane snapshots that are a square micron (millionth of a meter). The algorithm samples those and uses ML to analyze and order the data to generate and choose interesting patches, each 30 nanometers (billionths of a meter) on a side – usually regions around Ras and Raf proteins – for CG simulations.
The SC21 paper reported that the continuum simulation produced 20,507 snapshots that MuMMI processed to generate more than 6.8 million patches. The ML code evaluated these to choose 34,523 patches for CG modeling. The CG simulations identified more than 9.8 million frames relevant to Ras-Raf research, from among which the ML code chose just under 0.01%, or 9,632, for atomistic modeling. Each simulation portrayed up to 5 microseconds of interactions at CG scale and 50 to 60 nanoseconds at the more demanding atomistic scale.
MuMMI also sends in situ feedback between models, using sampled data from the atomistic model to tune parameters in the CG model and from the CG model to tune parameters in the continuum model. Previously, researchers often ran simulations, stopped to analyze and choose the next set, and repeated the process. In situ operation removes the human from the loop, Ingólfsson says.
“You get this effective multiscale, but it also is giving you the most detail,” he says. Without MuMMI’s mechanized workflow, researchers choose a limited number of systems and simulations to computationally explore. “Using a MuMMI-like framework, you are realistically exploring the environment. You can explore differences in concentrations in the membrane instead of just doing the ten or a hundred or a thousand” a researcher manually selects.
The Frederick National Laboratory scientists have been conducting experiments to verify results from the ALCC simulations and the groups are jointly composing manuscripts. In general, the data support conclusions from two-scale calculations indicating that local lipid compositions dictate how Ras collects and orients itself on the cell membrane.
The group is using a second ALCC allocation, for 740,000 node hours, to further Ras-Raf research. The team may extend the code to an additional scale, focused more on time rather than length, to follow Raf as it opens into multiple possible domains. The team also has generalized the code, making it useful for applications beyond cancer and biology, and it’s available via the GitHub repository.
Meanwhile, the researchers have secured a third ALCC allocation for 2022-23. Besides an added 350,000 node-hours on Summit, they’ll have 70,000 on Oak Ridge’s Frontier, the world’s first computer to run at exascale – more than a quintillion calculations per second.
Bhatia says the latest allocation will let the team test how well the code scales to the newest milestone but also make MuMMI even more adaptable. “Frontier will have a different architecture than Summit and Sierra,” the LLNL machine the code ran on first. “Future work will entail how we move all the pieces, make them more generalizable, so we can absorb those kinds of changes.”