
The Scientific Discovery through Advanced Computing program, better known in computing circles as SciDAC, launched 20 years ago last year – shortly after Robert B. Ross started at Argonne National Laboratory. Ross and SciDAC have been inseparable ever since.
“I was drawn to Argonne by the talented team in the math and computer science division,” Ross says. “Now I can really see how my work is impacting science in a variety of fields through SciDAC and the Exascale Computing Program. It’s an amazing community of domain experts in so many areas working together.”

Robert Ross. Image courtesy of ANL.
Ross began as a postdoctoral researcher in data management. He now directs the SciDAC RAPIDS Institute for Computer Science, Data, and Artificial Intelligence, supporting Department of Energy (DOE) Office of Science teams that adapt and apply computer science technologies to achieve scientific breakthroughs. RAPIDS stands for Resource and Application Productivity through Computation, Information, and Data Science.
Like SciDAC itself, RAPIDS connects computer scientists and applied mathematicians with domain scientists from across the energy sciences, from high-energy physics to earth systems science and more. RAPIDS focuses on helping them use Open Source Cluster Application Resources (OSCAR), DOE’s high-performance cluster computing tools spread throughout the country.
In January, Ross’ expertise in scientific data storage and management was recognized by the Association of Computing Machinery (ACM), naming him a Fellow. Only 1 percent of ACM members achieve that rank. He received a Presidential Early Career Award for Scientists and Engineers and has garnered no fewer than three R&D 100 awards for SciDAC-related innovations. And last year, he won the Ernest Orlando Lawrence Award in Computer, Information and Knowledge, DOE’s highest honor for mid-career scientists. He was cited for his “contributions in parallel file systems that underpin data storage on supercomputers, communication and input/output software that are foundations of scientific codes running on these platforms, monitoring tools that provide insight into how supercomputers are used in production, and simulation capabilities that enable ‘what-if’ evaluation of potential new supercomputer features and architectures.”
‘Artificial intelligence is impacting so many aspects of what we do.’
Ross and his team take on the challenges of capturing, organizing and making sense of the enormous amount of data DOE supercomputers generate while running simulations on energy problems both applied and basic, from designing new electric car batteries to exploring protein structure with beamlines and probing the universe’s evolution.
The tools he’s worked on have had surprisingly long shelf life for such a rapidly changing field. Early in his career, he says, “we developed an open-source storage system called PVFS that became the OrangeFS file system still in use today. We’ve also contributed to software that helps science teams store and retrieve data at very large scales through the ROMIO and Parallel netCDF tools.”
More recently, Ross and colleagues have built capabilities that improve the performance of storage systems by monitoring how applications use them – and that help facilities understand how to deploy the best platforms.
Besides making scientific data intelligible and accessible, SciDAC helps researchers in numerous other ways, including developing scientific code and moving it onto the new superfast exascale platforms expected to come on line between now and 2023.
“The most interesting thing going on right now is perhaps how artificial intelligence is impacting so many aspects of what we do,” Ross says. “We’re helping teams across the Office of Science use AI in their work, but we’re also working internally on using AI to improve our RAPIDS tools.”
“Teams often must train AI algorithms at massive scale. Supercomputers provide the speed to handle that task, producing models that classify data and predict results, helping screen for the best possible solutions.
AI’s increasing importance to supercomputing is spurring the drive for exascale capacity. “Scientists have realized AI can help accelerate their work,” Ross says. “AI can be used to build reduced-order models to represent their science a little more simply and, if you’re tactical about where you apply these things, you can accelerate simulation codes while still getting the level of fidelity that you need to answer your questions or maybe narrow down the area where you need more high-fidelity simulations.”
DOE researchers are also using AI to guide searches for good parameters or close fits to parameters within large high-dimensional spaces – many parameters with many potential values – than possible before. Good parameters, for example, depend on context and might help, for instance, boost a supercomputer’s speed and efficiency.
Computer scientists also are interested in control problems that revolve around a complex set of services. They want to predict when the computer system service needs more or less resources. “AI has a place here,”Ross notes, “and there are always different ways it fits in, but they all touch on exascale in some fashion.”
Heterogeneous computer architectures that use accelerators such as graphics processing units for AI can make it difficult for science teams to run on varying high-performance systems, Ross says. “So it’s driving the platform readiness piece of RAPIDS to be a little more important than maybe it was a few years ago when the answer was going to be an NVIDIA accelerator for many platforms. This is because the computing hardware landscape has become more complex, while just a few years ago the diversity we’re seeing now, particularly in processors, didn’t exist.”
The finesse of AI has displaced the brute-force model with system architectures that incorporate both more traditional CPUs and accelerators.
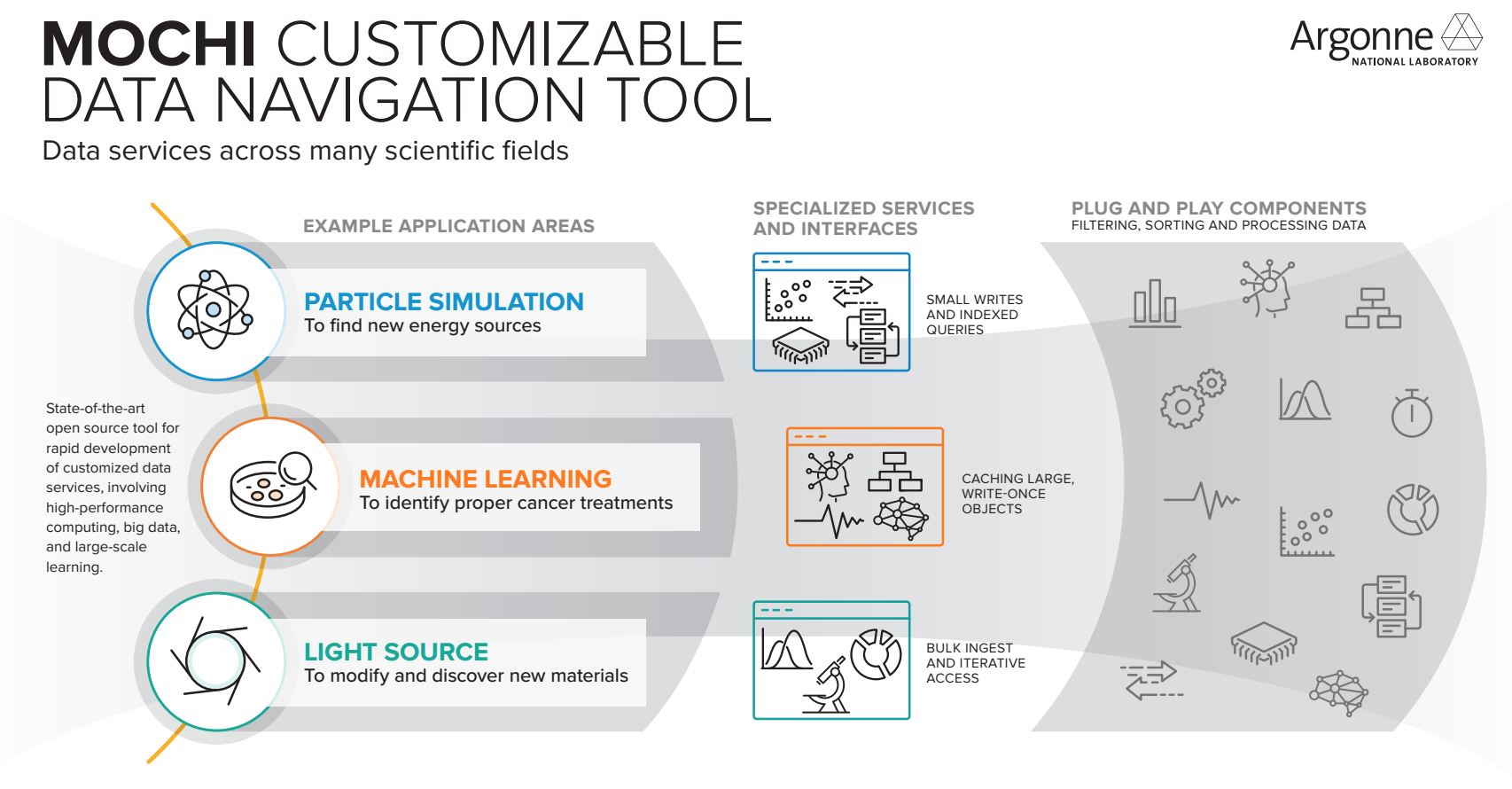 One of Ross’ favorite projects – and his most recent R&D 100 winner, last year – is Mochi, which helps teams build tailored data solutions and share components with each another to adapt to exascale. The software is designed so that if a user decides to make changes – where or how to store the data, for example – it’s simple and won’t disrupt the entire service.
One of Ross’ favorite projects – and his most recent R&D 100 winner, last year – is Mochi, which helps teams build tailored data solutions and share components with each another to adapt to exascale. The software is designed so that if a user decides to make changes – where or how to store the data, for example – it’s simple and won’t disrupt the entire service.
Mochi already has some users, including Intel, academia and the national labs, and they’re hopeful Mochi will “help an ecosystem of these kinds of services thrive in exascale and beyond,” Ross notes.
If one theme has emerged during his career, Ross says, it is this: People almost always need more data than they have – whether it’s more information from a simulation or about how a facility is operating.
“Early on, I didn’t appreciate how important this kind of situational awareness was as much as I could have,” he says. “And I recently started to appreciate how the structure, annotations and documentation we use are getting toward FAIR data standards” – findability, accessibility, interoperability and reusability, as an international consortium of scientists outlined five years ago.
“During the next decade, with learning becoming so important, we’re really going to need to get our heads around how our performance data and other things like that can be captured and stored in a way tools can best take advantage of.”