Quantifying the risks buried nuclear waste pose to soil and water near the Department of Energy’s (DOE’s) Hanford site in Washington state is not easy. Researchers can’t measure the earth’s permeability, a key factor in how far chemicals might travel, and mathematical models of how substances move underground are incomplete, says Paris Perdikaris of the University of Pennsylvania.
But where traditional experimental and computational tools fall short, artificial intelligence algorithms can help, building their own inferences based on patterns in the data. “We can’t directly measure the quantities we’re interested in,” he says. “But using this underlying mathematical structure, we can construct machine-learning algorithms that can predict what we care about.”
Perdikaris’ project is one of several sponsored by the DOE Early Career Research Program that apply machine-learning methods. One piece of his challenge is combining disparate data types such as images, simulations and time-resolved sensor information to find patterns. He will also constrain these models using physics and math, so the resulting predictions respect the underlying science and don’t make spurious connections based on data artifacts. “The byproduct of this is that you can significantly reduce the amount of data you need to make robust predictions. So you can save a lot in data efficiency terms.”
Another key obstacle is quantifying the uncertainty within these calculations. Missing aspects of the physical model or physical data can affect the prediction’s quality. Besides studying subsurface transport, such algorithms could also be useful for designing new materials.
Machine learning belongs to a branch of artificial intelligence algorithms that already support our smartphone assistants, manage our home devices and curate our movie and music playlists. Many machine-learning algorithms depend on tools known as neural networks, which mimic the human brain’s ability to filter, classify and draw insights from the patterns within data. Machine-learning methods could help scientists interpret a range of information. In some disciplines, experiments generate more data than researchers can hope to analyze on their own. In others, scientists might be looking for insights about their data and observations.
But industry’s tools alone won’t solve science’s problems. Today’s machine-learning algorithms, though powerful, make inferences researchers can’t verify against established theory. And such algorithms might flag experimental noise as meaningful. But with algorithms designed to handle science’s tenets, machine learning could boost computational efficiency, allow researchers to compare, integrate and improve physical models, and shift the ways that scientists work.
‘How do we bring in the physics, the domain knowledge, so that an algorithm doesn’t need a lot of data to learn?’
Much of industrial artificial intelligence work started with distinguishing, say, cats from Corvettes – analyzing millions of digital images in which data are abundant and have regular, pixelated structures. But with science, researchers don’t have the same luxury. Unlike the ubiquitous digital photos and language snippets that have powered image and voice recognition, scientific data can be expensive to generate, such as in molecular research experiments or large-scale simulations, says Argonne National Laboratory’s Prasanna Balaprakash.
With his early-career award, he’s designing machine-learning methods that incorporate scientific knowledge. “How do we leverage that? How do we bring in the physics, the domain knowledge, so that an algorithm doesn’t need a lot of data to learn?” He’s also focused on adapting machine-learning algorithms to accept a wider range of data types, including graph-like structures used for encoding molecules or large-scale traffic network scenarios.
Balaprakash also is exploring ways to automate the development of new machine-learning algorithms on supercomputers – a neural network for designing new neural networks. Writing these algorithms requires a lot of trial-and-error work, and a neural network built with one data type often can’t be used on a new data type.
Although some fields have data bottlenecks, in other situations scientific instruments generate gobs of data – gigabytes, even petabytes, of results that are beyond human capability to review and analyze. Machine learning could help researchers sift this information and glean important insights. For example, experiments on Sandia National Laboratories’ Z machine, which compresses energy to produce X-rays and to study nuclear fusion, spew out data about material properties under these extreme conditions.
When superheated, samples studied in the Z machine mix in a complex process that researchers don’t fully understand yet, says Sandia’s Eric Cyr. He’s exploring data-driven algorithms that can divine an initial model of this mixing, giving theoretical physicists a starting point to work from. In addition, combining machine-learning tools with simulation data could help researchers streamline their use of the Z machine, reducing the number of experiments needed to achieve accurate results and minimizing costs.
To reach that goal, Cyr focuses on scalable machine algorithms, a technology known as layer-parallel methods. Today’s machine-learning algorithms have expanded from a handful of processing layers to hundreds. As researchers spread these layers over multiple graphics processing units (GPUs), the computational efficiency eventually breaks down. Cyr’s algorithms would split the neural-network layers across processors as the algorithm trains on the problem of interest, he says. “That way if you want to double the number of layers, basically make your neural network twice as deep, you can use twice as many processors and do it in the same amount of time.”
With problems such as climate and weather modeling, researchers struggle to incorporate the vast range of scales, from globe-circling currents to local eddies. To tackle this problem, Oklahoma State University’s Omer San will apply machine learning to study turbulence in these types of geophysical flows. Researchers must construct a computational grid to run these simulations, but they have to define the scale of the mesh, perhaps 100 kilometers across, to encompass the globe and produce a calculation of manageable size. At that scale, it’s impossible to simulate a range of smaller factors, such as vortices just a few meters wide that can produce important, outsized effects across the whole system because of nonlinear interactions. Machine learning could provide a way to add back in some of these fine details, San says, like software that sharpens a blurry photo.
Machine learning also could help guide researchers as they choose from the available closure models, or ways to model smaller-scale features, as they examine various flow types. It could be a decision-support system, San says, using local data to determine whether Model A or Model B is a better choice. His group also is examining ways to connect existing numerical methods within neural networks, to allow those techniques to partially inform the systems during the learning process, rather than doing blind analysis. San wants “to connect all of these dots: physics, numerics and the learning framework.”
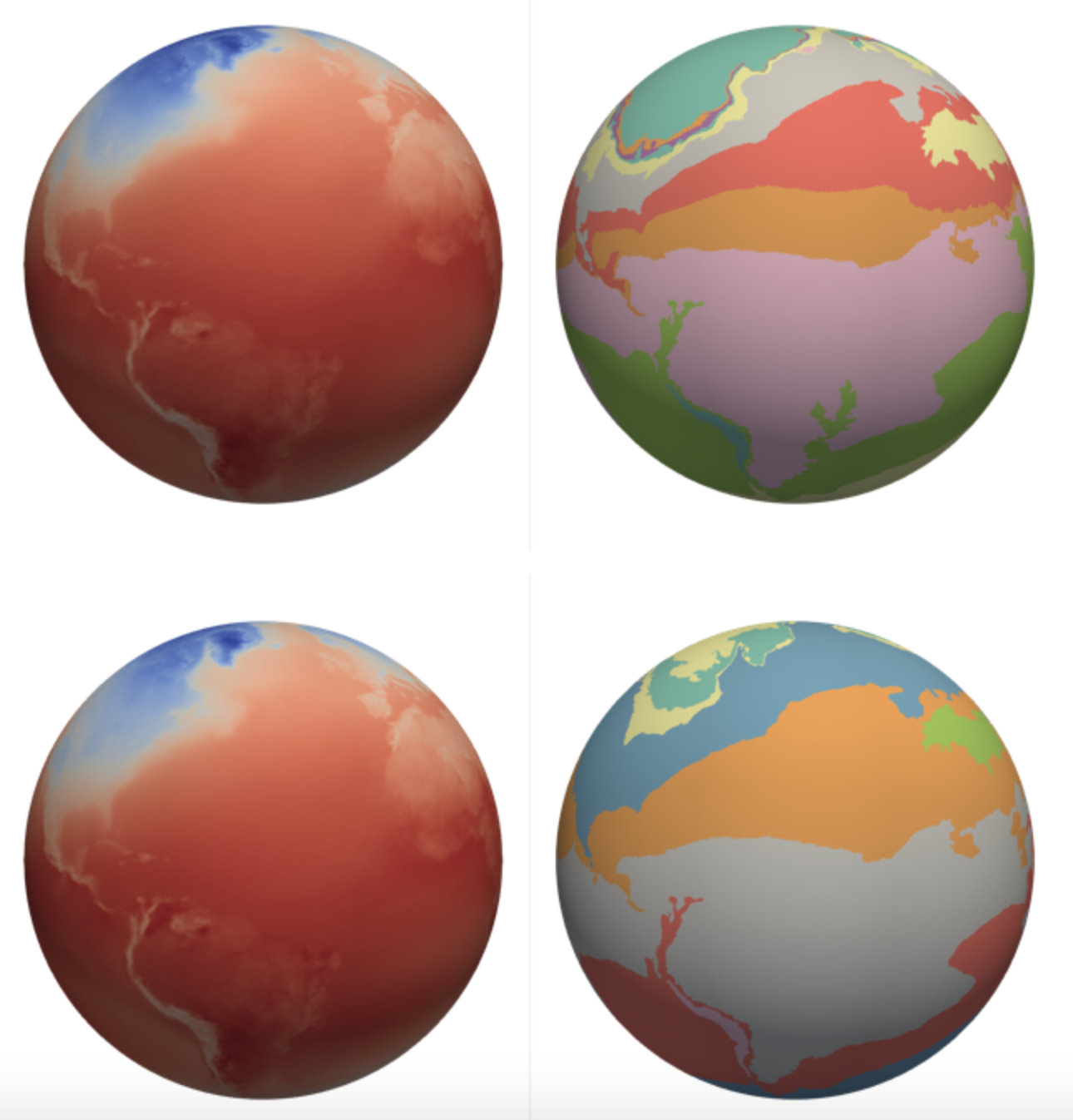
Machine learning also promises to help researchers extend the use of mathematical strategies that already support data analysis. At the University of Arizona, Joshua Levine is combining machine learning with topological data-analysis tools. These strategies capture data’s shape, which can be useful for visualizing and understanding climate patterns, such as surface temperatures over time. Levine wants to extend topology, which helps researchers analyze a single simulation, to multiple climate simulations with different parameters to understand them as a whole.
As climate scientists use different models, they often struggle to figure out which ones are correct. “More importantly, we don’t always know where they agree and disagree,” Levine says. “It turns out agreement is a little bit more tractable as a problem.” Researchers can do coarse comparisons – calculating the average temperature across the Earth and checking the models to see if those simple numbers agree. But that basic comparison says little about what happened within a simulation.
Topology can help match those average values with their locations, Levine says. “So it’s not just that it was hotter over the last 50 years, but maybe it was much hotter in Africa over the last 50 years than it was in South America.”
All of these projects involve blending machine learning with other disciplines to capitalize on each area’s relative strengths. Computational physics, for example, is built on well-defined principles and mathematical models. Such models provide a good baseline for study, Penn’s Perdikaris says. “But they’re a little bit sterilized and they don’t directly reflect the complexity of the real world.” By contrast, up to now machine learning has only relied on data and observations, he says, throwing away a scientist’s physical knowledge of the world. “Bridging the two approaches will be key in advancing our understanding and enhancing our ability to analyze and predict complex phenomena in the future.”
Although Argonne’s Balaprakash notes that machine learning has been oversold in some cases, he also believes it will be a transformative research tool, much like the Hubble telescope was for astronomy. “It’s a really promising research area.”