
The Aurora supercomputer – scheduled to arrive at the Department of Energy’s Argonne National Laboratory in 2021– stands to benefit countless fields of study from materials science simulations of defect formation at the molecular level to fluid dynamics computations for experimental engines.
Aurora will be based at the Argonne Leadership Computing Facility (ALCF), a DOE Office of Science user facility. It will be among the nation’s first exascale computers, capable of performing a quintillion (a billion billion, or 1018) calculations per second, about eight times faster than Oak Ridge National Laboratory’s Summit, currently rated as the world’s most powerful supercomputer.
“The compute part of our resources is growing at an incredible rate while the rate of the input-output – the rate at which we can write the data to disk – is not keeping pace,” says Joseph Insley, who heads ALCF’s visualization and data analytics efforts. “We can’t save nearly as much of the data as we produce. As that gap continues to widen, there’s going to be lost science. We’re not going to be able to analyze all the data that we’re computing using conventional postprocessing methods.”
Numerous efforts across the high-performance computing community are focused on developing new tools to help users of leadership-class resources cope with the flood of data the new machines generate. In one such collaboration, Argonne computer scientists are working to incorporate data analysis methods known as in situ – as the calculations happen – and in transit –moving the data – into computations.
Supported by the Office of Advanced Scientific Computing Research within DOE’s Office of Science, the collaboration includes Lawrence Berkeley and Oak Ridge national laboratories and two companies, Kitware and Intelligent Light. Along with Argonne, each of the five partners contributes to the project’s infrastructure and science-facing aspects.
“One of Argonne’s main tasks has been doing the science outreach to make sure that these tools are applicable to the software that is important to DOE scientists,” says Nicola Ferrier, a senior computer scientist at the lab.
Supercomputing resources usually emphasize simulation capabilities. More recently, however, large-scale computing’s focus has expanded to comprise three main pillars: simulation (simulation-based computational science), data (large-scale data-intensive computing), and learning (machine learning, deep learning, and other artificial intelligence capabilities). This trend will only accelerate in the exascale era.
“The ultimate goal is to enable the advancement of science,” Insley says. “That’s what these three pillars are intended to accomplish. And as the scale of the data continues to grow, advanced visualization and analysis capabilities are needed to help researchers gain additional insights.”
‘The goal is to be able to use lots of different infrastructures without having to re-instrument your code all the time.’
Visualization and analysis traditionally follow simulations, Insley explains, when “you write your data out, and when you’re done you go back and look at it. We’ve already reached the point where we can’t save all the data.”
Scientists now must look at their data while the information is still in memory to ensure that no science is lost. Unfortunately, they don’t always know ahead of time what they’re seeking.
The high-energy physics community has been adapting to this challenge for decades. The major research collaborations conducting experiments at the Large Hadron Collider at CERN, the European particle physics laboratory, generates such vast quantities of data that most of it is quickly lost. But physicists have developed theories that help them determine what phenomena to look for in the LHC’s subatomic particle collisions. This lets them write algorithms to instantly identify which data must be saved to long-term storage for further analysis.
A myriad of scientific disciplines, however, will tap Aurora for research using a variety of computational tools. They will need a more generic interface to build upon.
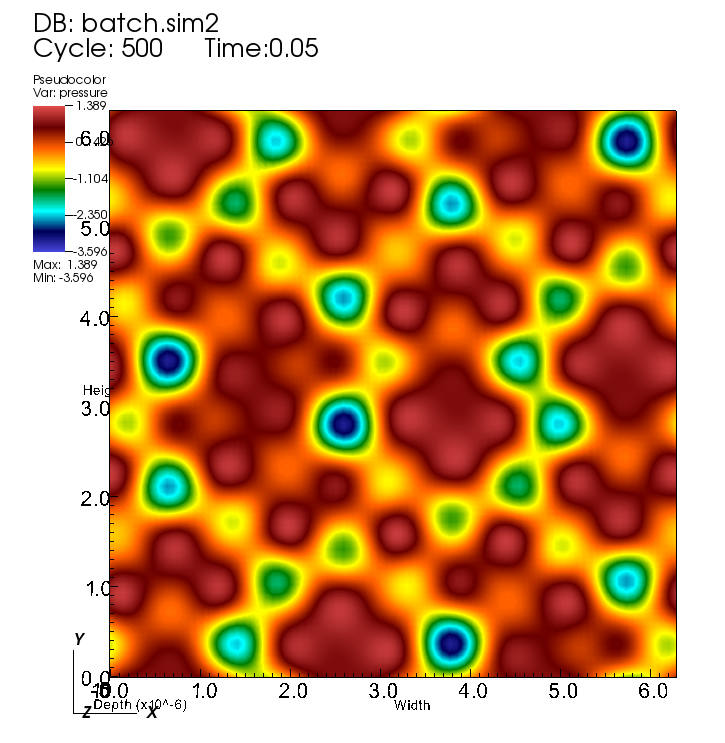
A snapshot of pressure variations in a computational dynamics simulation conducted at the Argonne Leadership Computing Facility. This is an example of the SENSEI analysis and visualization system for designing large-scale computational experiments. Visualization courtesy of Will Usher, SCI Institute, University of Utah, from science by Mathew Cherukara, Badri Narayanan, Henry Chan, and Subramanian Sankaranarayanan, Argonne National Laboratory.
A scalable in situ analysis and visualization generic data interface called SENSEI will provide that link. SENSEI lets researchers prepare their simulation code just once – and in a fairly easy way – enabling them to leverage a given analysis infrastructure on the back end of a computer system.
The in situ infrastructures under testing with SENSEI include Catalyst, Libsim and ADIOS (Adaptable IO System). Various scientific simulation codes, including LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator), are used to demonstrate and evaluate the framework.
“The goal is to be able to use lots of different infrastructures without having to re-instrument your code all the time,” Ferrier says. “By using this SENSEI bridge you can choose what data generator – what simulation code, for example – and what back-end visualization or analysis tool you want to run.”
LAMMPS is an especially well-known simulation code and is widely used for materials science and allied fields. “It scales well, meaning that it efficiently runs on the largest supercomputers available,” says Silvio Rizzi, an ALCF assistant computer scientist. “It’s also used in multiple disciplines, including materials science and molecular dynamics. It’s a logical target to prove the solutions we are implementing. It’s also one of the main applications that will be targeting exascale.”
A supercomputer usually is divided into multiple compute nodes that talk to each other through a network, Rizzi says. In the case of in situ methods, simulation and analysis “live in the same nodes and they share the resources. They share the CPUs. They share the memory.”
Sometimes, however, especially when simulations make heavy memory demands, researchers prefer to move their data out of the shared nodes and analyze them in a different location. That method, called in transit, might require moving data through the network to different nodes of the same supercomputer, to a smaller resource such as a visualization cluster, or even off location.
Argonne researchers already have developed SENSEI adaptors for use with LAMMPS. Applications include devising models to study directed self-assembly, in which molecules organize themselves into specific, predetermined patterns. The International Technology Roadmap for Semiconductors has identified directed self-assembly as critical for advancing miniaturization in the semiconductor industry.
LAMMPS also can simulate the growth of large-area, two-dimensional materials used in flexible displays, light-emitting diodes, touch screens, solar cells, batteries and chemical sensors. Such simulations help researchers understand how various synthesis methods affect the properties and performance of devices consisting of two-dimensional materials.
In related work, Argonne researchers have adapted a popular simulation software package called NEK5000 for use with SENSEI in modeling experimental internal combustion engines. The generation of turbulence during an engine’s intake stroke is critical to its efficient operation. It’s also the most challenging aspect of the process to simulate, Rizzi noted.
Success in these efforts will have broad impact. As Insley puts it, “while the scale and complexity of the problems, and accuracy of the solutions, that people will be able to compute will surely be greater with exascale resources, in situ capabilities will be critical for gaining scientific insight from those solutions.”
Editor’s note: Republished from DEIXIS online magazine.