The NOvA project at the Fermi National Accelerator Laboratory aims to catch an elusive, shape-shifting particle called the neutrino in the act of transforming from one flavor, or type, into another.
Researchers direct a high-intensity beam of neutrinos through one detector at the lab in Batavia, Illinois, and intercept it again with a 14,000-ton detector at Ash River, Minnesota, 500 miles away. How proportions of the three neutrino flavors in the beam change between what the near and far detectors find indicate that neutrinos have morphed in transit.
Each time the team passes a beam of the particles through the near detector at Fermilab, the instrument yields an enormous data load, which then must be processed. In a recent experiment, the near detector generated 56 trillion bytes as the detector captured 114 million particles, mostly neutrinos.
This huge data trove poses a challenge: Fermilab and many other research facilities don’t always have enough computing resources available to analyze results of their experiments.
The data influx will only increase as the international neutrino community unites to design and eventually operate the massive Deep Underground Neutrino Experiment (DUNE), as the Large Hadron Collider (LHC) at CERN in Switzerland ramps up, and as astrophysicists spin out their own data-intensive experiments and simulations.
“The way our science is evolving in the high-energy frontier, in about 10 years we’re going to be facing an explosion of data coming out of the LHC accelerator,” says Panagiotis Spentzouris, head of Fermilab’s Scientific Computing Division. “And that poses some very stringent requirements on the type of computing infrastructure you need to deal with analysis. If we look at the computing resources we own today and you scale it to satisfy these requirements, this will be cost prohibitive. So we need to be smarter.”
Even with current levels of experimental data, the demands on computational power can take large, unavoidable swings as research groups begin big simulations, crunch experimental results or race to prepare their latest findings for major conferences. “You do not have steady state,” he says. “You have peaks and valleys.” That means providing additional computational power during the peaks and finding new ways to keep computers working during the valleys.
To press more computers into service during peaks, researchers at some national laboratories have experimented with commercial cloud-computing services, such as Amazon Web Services (AWS), Google Cloud Platform (GCP) and Microsoft Azure. These efforts solve the short-term problem of bringing more cores to bear on particular problems. But in the long term, facilities also must fill the valleys, quickly assigning projects to computer cores left idle by large projects that don’t need every bit of a machine’s available capacity. As Spentzouris says, anytime “a high-performance machine is idling is a loss of money.”
A collaboration with Google announced at SC16 lets Fermilab add 160,000 virtual cores and 320 trillion bytes of memory to the Compact Muon Solenoid experiment.
To achieve that efficiency, Spentzouris and his co-workers launched a project in June 2015 called HEPCloud (the HEP stands for “high-energy physics”). The group is developing an interface within HEPCloud that will streamline the movement of jobs among a variety of computing resources, for instance local clusters and computer grids such as the Open Science Grid (OSG) to commercial clouds to high-performance machines at national labs.
HEPCloud’s central feature is a decision engine that, in real time, automates integration of multiple parameters, such as availability, cost, and workflow compute needs, to use computing facilities efficiently. Besides invoking cloud computing to handle peaks on demand, HEPCloud is fully integrated into OSG, routing jobs to idle cores on academic grids and always choosing the right resources for each job to constrain costs.
The team is developing the decision engine and challenging it with data available from Fermilab colleagues working on three major projects: The Compact Muon Solenoid (CMS) at LHC, NOvA and the Dark Energy Survey (DES). In January 2016, they used one of AWS’s many sites to crunch numbers from a CMS project. The demonstration pumped up the total computational resources by adding 58,000 cores to the already available 150,000.
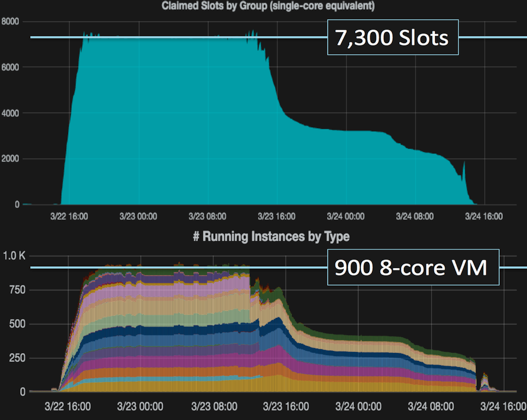
After the NOvA experiment described at the beginning of this article, the group used HEPCloud to reconstruct the near detector’s 56 trillion bytes and 114 million particle impacts, burning through about 260,000 processor hours and yielding 124 trillion bytes of data. HEPCloud parceled out jobs to machines at three AWS sites, and the decision engine independently assigned each task to an appropriate instance, or mix of cores, memory and storage. That meant jobs were executed on less expensive instances when possible, and more demanding tasks went to the most economical instances available.
The project not only helped sharpen operational practices and showed HEPCloud’s ability to handle offsite workflows involving high levels of data input and output, but it also generated results that were useful to the NOvA research group. “I fully expected my team to succeed, but I did not expect them to deliver science out of the pilot,” Spentzouris says.
At the recent SC16 supercomputing conference in Salt Lake City, the team announced jointly with Google that GCP is now a supported provider for HEPCloud. The collaboration lets Fermilab add 160,000 virtual cores and 320 trillion bytes of memory to the CMS experiment.
HEPCloud grew out of two developments in the high-energy physics community, the first being a move toward offsite resources. “We weren’t the first ones to try to go to commercial clouds,” Spentzouris says. Brookhaven National Laboratory “started using (a cloud) for one particular experiment, Atlas, which is one of the LHC experiments. So that was appealing.”
The second development was the DOE Office of Science’s Advanced Scientific Computing Research program’s call to complement existing computing-intense applications with data-intense applications. “That plus the information about people playing with commercial clouds kind of created this idea,” Spentzouris says. “Why not develop a facility that will give you access to all of the above and furthermore will have intelligence?”
Now that HEPCloud has proven it can manage projects while controlling costs, the team aims to prepare it for use by HEP researchers in 2018. Spentzouris and colleagues are now working to connect with high-performance machines at the national labs, beginning with the National Energy Research Scientific Computing Center (NERSC) at Lawrence Berkeley National Laboratory.
Here, the HEPCloud decision engine also will have to incorporate policies. “HPC computing facilities,” especially high-performance computing centers like NERSC, “are stricter about who they accept,” Spentzouris says. “We’re making a lot of progress in changing the way we do our reporting and the way we implement our security controls.”
He notes that many such less-than-dramatic challenges – “from little to medium” – remain. “In the end there are no showstoppers.”