Like professional athletes, supercomputers must play smarter just to stay in the game.
Once athletes reach their personal limits for strength, speed, and skill, all room for improvement lies in game play – finding ways to optimize the resources at hand. Yet the question remains: After committing an error, does an athlete return to top form?
It all comes down to resilience.
High-performance computing (HPC) faces a similar challenge as it approaches exascale capability – the capacity to complete a million trillion calculations per second or handle millions of trillions of data bits. Resilience is a big problem because the sheer size and complexity of hardware in each machine makes failure inevitable.
Hardware also is near its limits for size and efficiency. As designers shrink circuits and reduce voltages, systems are more susceptible to soft errors – the unpredictable and unavoidable switching of 0s to 1s and vice versa that low-level noise or ambient radiation can trigger without hardware damage.
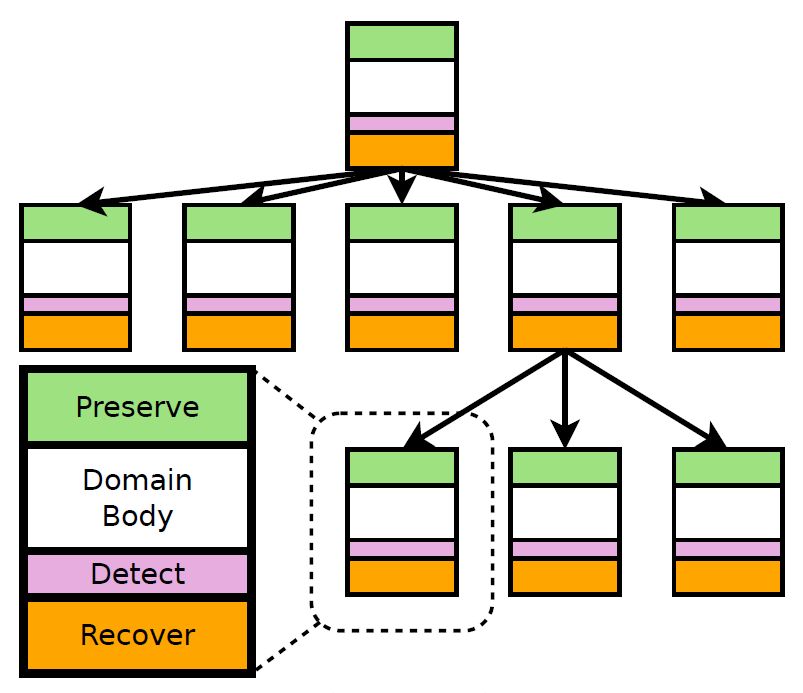
A University of Texas at Austin (UT) computer scientist and his colleagues are collaborating with Cray Inc. to develop a new approach, called containment domains. The concept could bring resilience strategies into play when and where they’re needed most.
“We are working to bring resilience to a footing similar to more traditional programmer concerns,” says Mattan Erez, UT associate professor of electrical and computer engineering. “Containment domains are the abstraction we came up with that satisfies these goals and can be used consistently across system and programming layers.”
Several research groups also are developing algorithms that tolerate faults.
A containment domain is a programming device that isolates an algorithm until all its components and iterations have been completed, checked for accuracy, and corrected, if necessary. Only after the resulting data pass these tests are they allowed to serve as inputs in subsequent algorithms.
The group first devised the idea under the Echelon Ubiquitous High Performance Computing program, supported by the Defense Advanced Research Projects Agency (DARPA), Erez says. He’s completing the first year a DOE Early Career Research Award supporting his project to develop promising solutions to the problem of resilience.
On the Echelon project, Erez and his group were to develop new approaches for resilience by exploiting the hierarchy of the modern supercomputer and enabling programmers to handle diverse kinds of errors differently. Their goal: give programmers tools and abstractions they need to improve resilience.
Today, most supercomputers handle errors the same way PC users guard against software crashes. At regular intervals, a supercomputer does the equivalent of pressing “control-S,” storing the current state of calculations in memory as a so-called checkpoint. If an error occurs, the supercomputer can roll back to that preserved state and resume work, much as PC users restart from a saved version of their work.
Saving and rebooting are mere inconveniences for a PC user, but the HPC equivalent of preserving state and rolling back is vastly more expensive. Preserving a global checkpoint burns valuable runtime and resources. The amount of data that can shuttle between processors and memory also does not scale – as the rate of calculations goes up, the pipeline to memory stays the same. This bottleneck limits how much data can be stored in a checkpoint and how often checkpoints can be made. By some estimates, petaflops (thousands of trillions of calculations) and exaflops systems could spend more than half of their time just saving data for global checkpoints.
Rolling back to retrieve preserved data is even more costly. First the machine has to discard the work done since the last checkpoint. Then it must recover that checkpoint and re-execute – that is, repeat the calculations it threw out, which consumes time. “The balance between preserving data frequently and re-executing for a longer period of time is optimized to minimize overall degradation of performance,” Erez says.
Several strategies to deal with errors have emerged over the past few decades. For example, an executable assertion, also known as a sanity check, can test whether a system’s basic operations are functioning properly with a quick challenge.
More sophisticated strategies hinge on the idea that some errors are less important than others. “Not all computations require the same amount and type of error protection,” Erez says. In fact, some errors fall into a category called “tolerable imprecision,” because they don’t make any difference. In other cases, algorithms naturally tolerate faults; they will reach the correct answer even after silent soft errors occur.
“Many iterative algorithms converge toward a solution,” Erez says. “An error may slow the convergence rate but is unlikely to change the answer. Many randomized algorithms will also be unaffected by errors because the errors get washed out statistically.”
Several research groups also are developing new algorithms that tolerate faults. The programs grind away, eventually converging on the correct answer despite encountering errors along the way.
Other approaches try variations on checkpointing. Multilevel checkpointing stores the states of individual nodes locally – in or near the nodes – and fairly frequently. The nodes are checkpointed individually, then as small groups, and then in groups of groups of increasing size. The computer can recover data at the most efficient level, rolling back only the smallest group needed to reach a point before the fault. In distributed checkpointing, a handful of nodes save portions of the computation’s state for one another. If any one node fails, much of the data can be retrieved from its neighbors.
Like multilevel checkpointing, containment domains also preserve the state of a small part of the system before an algorithm begins. However, containment domains also sequester the algorithm from the rest of the system so each error can be ignored or corrected as appropriate.
Corrective measures then come into play within the containment domain. Any recovery of data is uncoordinated with the rest of the system. So containment domains avoid an expensive hazard of multilevel checkpointing: They do not interact with neighboring nodes, which could trigger a domino effect of unnecessary rollbacks.
Because containment domains allow the use of multiple mechanisms for preserving calculations, they offer many advantages. First, they are fine-grained, confining algorithm checks to the optimal number of necessary nodes – that is, as few as possible.
Second, containment domains are expressive, giving programmers the flexibility to embed the appropriate fault-detection and data-recovery strategies into each containment domain, depending on the algorithm, using relatively few lines of code.
Third, containment domains are tunable. They let programmers assign each error type a weight, based on the algorithm’ context. As a result, when an error is detected, the correction is a nuanced response of appropriate measures.
Finally, with the programmer’s knowledge of the running algorithms, containment domains also may exploit the fact that different nodes redundantly store the same data for performance reasons. Error-ridden data in one node may be restored not from a checkpoint but from another node using the same information.
As HPC expands toward exascale capability, small errors could cause big problems. Containment domains are likely to help scientists run more efficient algorithms on supercomputers, yielding more reliable answers, faster, to the big questions that only these big machines can address.