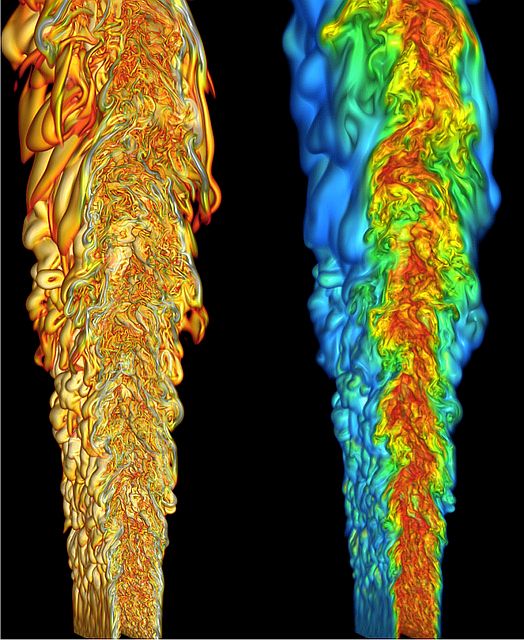
Ramanan Sankaran and his Oak Ridge National Laboratory colleagues have been setting up to run their combustion simulations on Titan, the world’s most powerful supercomputer. But before they could explore complexities that lie at the heart of combustion, they had to modernize their code.
To run their combustion science simulation code efficiently, they spliced together two approaches, creating a hybrid that boosts the parallel processing available on Titan’s 18,600-plus node architecture. What Sankaran’s team did will become increasingly crucial as high-performance computing moves toward the exascale.

Ramanan Sankaran
The cross-pollination lets them “make full use of all the processing power and not have any part of the computation become a bottleneck,” he says. Without that option, the programmers quickly realized they were already reaching the limits of performance.
Sankaran, trained as a mechanical engineer, has worked for almost a decade on the combustion code, known as S3D, developed at Sandia National Laboratories in California and at Oak Ridge in Tennessee. S3D is a “massively parallel direct numerical simulation solver for turbulent reacting flows,” says a paper Sankaran co-wrote and was presented at SC12, the annual fall supercomputing meeting.
Sankaran also is part of a Sandia-led group awarded 100 million processor hours of supercomputing time at Oak Ridge to run numerical simulations of flame phenomena under the Department of Energy’s Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program.
By expressing its governing equations in the form of three-dimensionally arrayed grids, S3D – written in Fortran, an old language familiar to scientists and programmers – can describe what happens when hundreds of different kinds of molecules undergo thousands of different reactions within spaces ranging from centimeters to a few microns, Sankaran says.
‘Even before we started thinking about using GPUs, it was clear we would need more than that single level of parallelism.’
That means it can simulate what may happen in combustion chambers of the future, when fuels from varied sources – including those from dirty oil sands – must somehow burn cleanly to improve energy efficiency and reduce pollution, including climate change-causing exhaust gases.
S3D can run on hybrid supercomputers that combine traditional central processing units (CPUs) with accelerators such as graphics processing units (GPUs), best known as a staple of computer gaming.

Circuit boards await installation at the Oak Ridge Leadership Computing Facility (OLCF) to build Titan, the world’s most powerful supercomputer for open science, with a theoretical peak performance exceeding 20 petaflops (quadrillion calculations per second). Image courtesy of Oak Ridge National Laboratory.
Titan itself is a Cray XK7 system that combines the calculating power of 18,688 computing nodes, each bearing a 16-core AMD Opteron CPU linked to and interacting with an NVIDIA Tesla GPU. Titan was unveiled last October and in November the TOP500 organization rated it as the world’s fastest computer, with a benchmarked speed of 17.59 million billion floating-point operations a second, or 17.59 petaflops.
S3D, in turn, is one of six science application codes that will run first to challenge Titan’s hardware.
For these science applications, it’s crucial that Titan’s processors are programmed to perform the same or related calculations at many, many points at the same time, experts say. GPU architectures inherently compute in a parallel way. But CPUs, the workhorses of the computing realm for many years, traditionally were coaxed into real parallelism, notably within so-called vector supercomputers pioneered by Cray back in the 1970s.
In the SC12 paper, Cray computer scientist John Levesque, Sankaran and mechanical engineer Ray Grout from the National Renewable Energy Laboratory in Golden, Colo., describe “an approach that can be used to rewrite an application for both performance and portability on the next generation of high-performance computers” by hybridizing the S3D code to operate in three distinct parallel ways within Titan.
At the outset, Sankaran notes, S3D was written to express one basic level of parallelism, called the message passing interface, or MPI. This topmost level of parallelism can operate in all of Titan’s CPUs via the machine’s Cray Gemini network interconnects.
He likens MPI to office workers jointly attacking a problem. “They are all computing in a distributed mode. Let’s assume some write the problem and hand it off to different workers to solve portions of it. So what they do is split the computing loads across multiple nodes – multiple processors that are connected to a network.”
Sankaran points out that a shortcoming of MPI is that “as each worker computes an answer, they have to exchange messages to keep everybody up to speed. But they cannot read each other’s memory directly. They cannot read minds.”
His programming team quickly realized the message-passing-only mode would quickly saddle the system with something like 300,000 MPI-only tasks to perform at once. “Even before we started thinking about using GPUs, it was clear we would need more than that single level of parallelism.”
So they decided to combine MPI with a second kind called OpenMP or, in programming lingo, “shared-memory thread-based parallelism.” OpenMP office workers are organized in groups. “Workers in a group share the tasks better and are aware of what others in the group are working on without explicitly passing messages,” he says.
The programming team started porting into S3D what they call extra “hybrid parallelism” by combining MPI with OpenMP. In the process they made sure to retain as much of the programmer-friendly Fortran structure as possible because some of its embedded coding also is vital for future high-level simulation work.
As technicians began installing Titan’s GPUs, Sankaran’s group started adding a third level of parallelization, SIMD, for single instruction, multiple data.
Extending the MPI office analogy to SIMD, Sankaran explains that “groups of workers are thinking and doing the same thing, but on different pieces. They are pretty much doing the same thing at the exact same clock cycle.” SIMD is similar to the vector parallel processing done by the old Cray supercomputers and comes naturally to GPUs, where it operates in Titan.
The hybrid approach got an additional boost in 2011 with the announcement of the OpenACC programming standard, developed for parallel computing by Cray Inc., NVIDIA, and the Portland Group, a supplier of programming tools called compilers. CAPS, a processor applications firm, also provided support.
Sankaran’s group enthusiastically incorporated OpenACC in their hybrid S3D code because the standard can target both CPUs and GPUs and lets programmers continue using legacy software in different parallel processing architectures. This spirit of flexibility also means a compiler can largely self-load OpenACC, the way Sankaran’s team handled it in their Titan work.
Titled “Hybridizing S3D into an Exascale Application using OpenACC” and subtitled “an approach for moving to multi-petaflops and beyond,” the SC12 paper refers both to Titan and to the next generation of supercomputers.
In the coming exascale world, where machines will operate a thousand times faster than in the petascale, experts say programs will have to coordinate and keep busy more than 100 million massively parallel processing cores. And teams like Sankaran’s must find ways to shield programmers from massive overload.