Part of the Science at the Exascale series.
Alex Szalay looks to the skies to study the universe’s largest structures. Frank Würthwein examines evidence of matter’s tiniest components. Both are counting on the next generation of computers to drive their discoveries.
What unites Szalay, the Alumni Centennial Professor of Astronomy at Johns Hopkins University, and Würthwein, a physics professor at the University of California, San Diego, is their need to move and sift an enormous amount of data. They’re testing the capacity of computers available today while thirsting for ones capable of an exaflops (a million trillion calculations per second) and of moving and storing an exabyte (a million trillion bytes) of data.
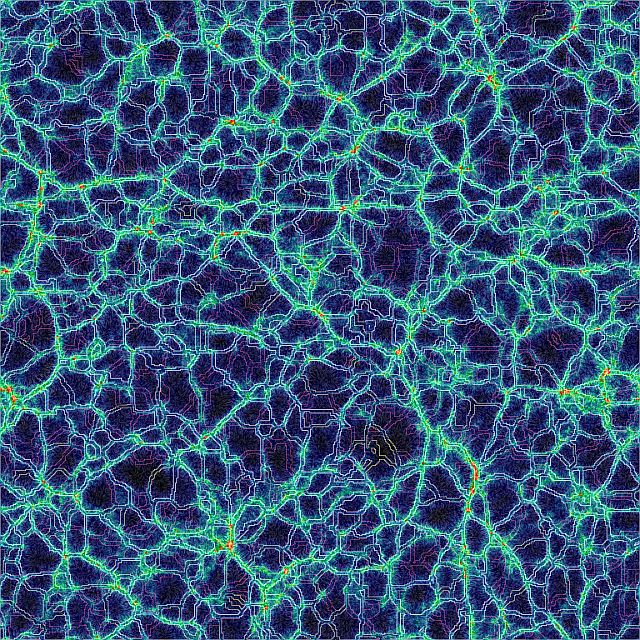
Szalay studies how the billions of galaxies that comprise the universe are distributed through space. It may look like chaos, he says, but there are patterns.
Galaxies “not only form so-called groups and clusters, which are very dense concentrations, but we also see really beautiful networks of threads, filaments and balls,” says Szalay, who holds a dual appointment in Johns Hopkins’ computer science department. How the galaxies are distributed can provide hints about the early universe and how it formed.
Szalay bases his interpretations on computer simulations and on observational data, including the Sloan Digital Sky Survey (SDSS), a multiyear effort to capture the sky from North America in exacting detail. It created a three-dimensional map containing nearly 1 million galaxies and generated a database of more than 100 terabytes – 100,000 gigabytes.
Szalay’s group has a computer with 1.2 petabytes of storage – 1,200 terabytes, or more than a million gigabytes – to handle data from the SDSS and from simulations collaborators have performed on the Jaguar supercomputer at Oak Ridge National Laboratory (ORNL).
It’s just one of the first waves in a flood of data. Projects on the horizon include the Large Synoptic Survey Telescope (LSST), to be built in Chile. Using a 3,200-megapixel camera (a consumer’s typical digital camera has fewer than 10 megapixels), it will capture detailed sky images every 15 seconds and depict the entire sky once every few nights.
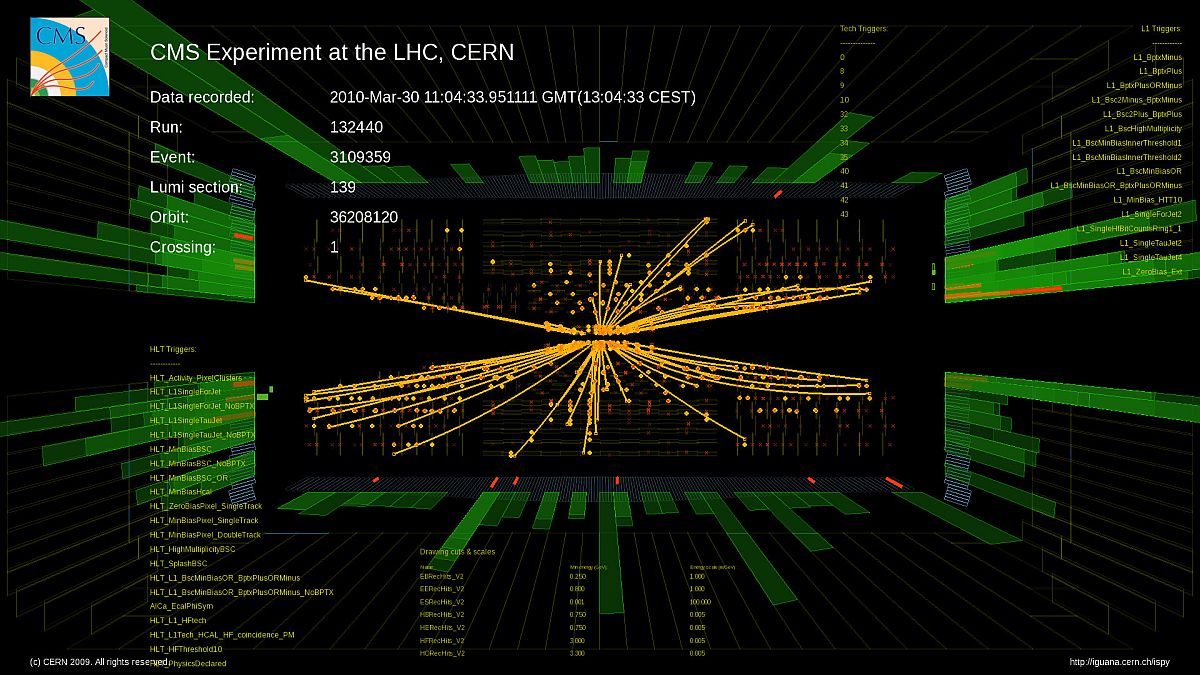
Layers of detectors in the Compact Muon Solenoid experiment watch for evidence of new particles created in the collision of protons or heavy ions in the Large Hadron Collider (LHC) at CERN, the international physics facility on the border between France and Switzerland. This display shows events tracked in the collider. Scientists believe the LHC will generate evidence of new particles and physics – perhaps even mysterious dark matter. Image courtesy of CERN.
That means tens of petabytes of data each year to store and analyze. Any changes in the stars the LSST spots also will be disseminated around the world in seconds so astronomers can turn their telescopes toward them.
To cope with the onslaught, Johns Hopkins is building a new system capable of handling 5.5 petabytes of data. It’s designed to maximize the number of input-output operations per second – a measure of the amount of data a computer can move and record. Most computer designs emphasize processor counts and flops – a measure of processing power.
Szalay’s goal is to build a system with the best trade-offs to deal with the new, data-intensive scientific paradigm – one that complements the processing power of the latest generation of supercomputers. “In the exascale world, of course, all this also will be true except that we will have to push it to 1,000 times larger scale.”
That capacity could change astrophysics and cosmology. Satellites and other instruments are seeking evidence of the dark universe – the invisible dark matter and dark energy that make up more than 96 percent of the universe. Exascale computers will give scientists the tools to interpret mounds of data these instruments produce.
Meanwhile, accelerators like the Large Hadron Collider (LHC) and the Tevatron at the Fermi National Accelerator Laboratory near Chicago are designed, in part, to create dark matter for study here on earth.
‘Computing has allowed us a level of nimbleness in this experiment that I have never seen.’
That’s Würthwein goal. Nearly every day, he’s in touch with graduate students and other researchers in Switzerland. His schedule often revolves around theirs, nine hours later than what the clock says in his office.
It’s all so Würthwein gets the most out of data from experiments at the LHC, the world’s most powerful particle accelerator. Its main goal is to detect the Higgs particle, the last piece predicted by the Standard Model that unites all known physical forces, other than gravity, and the particle believed to impart mass to all particles. But Würthwein is hoping to see dark matter, too.
Located in a circular tunnel under the Swiss-French border, the LHC smashes particles into each other at nearly the speed of light, generating short-lived particles and providing insights into the fundamental components and forces of matter. Würthwein works with the Compact Muon Solenoid, or CMS, one of four huge particle detectors at the LHC.
When it hits its full power of 14 tera electron volts (TeV), the LHC will be seven times more potent than the Tevatron, the previous most-powerful accelerator. Such an energy leap occurs only once every two or three decades, Würthwein says, and opens the door to spotting unexplored areas of physics.
“You can sort of think of it as going from ice to water or from water to vapor in understanding the most fundamental parts of nature. Going up in the energy scale is not just a matter of being better, higher, faster but also a matter of having a really qualitative shift and having a chance to prove something that could very well be surprising and new.”
The LHC will collide thousands of particles – protons or lead ions – every second, producing about 10 petabytes of data each second. Electronic filters will discard most of it as previously-known physics and record just a few hundred megabytes per second in real time. Even so, Würthwein expects the CMS to yield around 10 petabytes of data each year, and by the end of the decade, physicists will face datasets on the order of an exabyte – 1,000 times bigger than a petabyte. All of it must be analyzed in search of the exceedingly rare event that indicates the presence of the Higgs particle or dark matter.
That makes computing an integral part of the science. “Every generation of experiments that we do in high energy physics has one or more novel technologies,” Würthwein says. “And one of the absolutely novel technologies we have this time around is the way
we use networking, storage and computing in general.”
Historically, the lab hosting an accelerator experiment also hosted the data and most of the computer analysis. But from the moment the LHC began the bulk of its interactions this year, the data has streamed to multiple labs via high-speed networks. Data gathered from particle collisions in Europe one day generally are available for analysis in San Diego the next.
“Computing has allowed us a level of nimbleness in this experiment that I have never seen in any previous experiment,” Würthwein says. “The speed with which people look and find and understand things is just unprecedented.”
But the need for computing power is constantly growing because “whenever you have a new, bright idea to search for, you’re not going to use just the latest data,” Würthwein says. “You’re going to use all the data.”
That’s why he’s depending on exascale computing. “I’m envisioning my data samples growing so large in the near future that if I don’t get it, I’m going to be in trouble.”
While handling exabytes of data is more important to Würthwein than having exaflops of performance, Szalay wants both. Computer simulations are needed to predict what satellites and detectors will see in their search for strange physics in the galaxy. But if the simulations aren’t sufficiently detailed, “we may get the prediction completely wrong,” Szalay says. Exascale computers will enable simulations with an unprecedented level of precision – perhaps modeling galaxies down to the level of individual stars, rather than with clumps many times larger.
“It would be foolish to say that, OK, in 10 years when we get to exascale we can do the real thing, because I’m sure that new challenges will appear,” Szalay adds. “But certainly a lot of things that we are kind of dreaming of today would be totally enabled.”
And without it, Würthwein says, significant discovery could be stymied. “If you want to guarantee that the data is exploited to the fullest extent, then you have to have computing at a scale so that this can actually be done. If that’s not possible, then what you will end up seeing is only a very limited subset of science” – the least-risky science.