Complexity lurks within soap bubbles. These ubiquitous lathers may perform simple jobs like washing our hair, clothes, dishes and surfaces, but down deep they’re convoluted combinations of molecules called surfactants.
Such molecules have a dual nature, combining properties that allow them to mix well with both water and oil. In the right combinations, they clean the hair and body and lift greasy stains.
Though they have many applications, the complexity of surfactant mixtures makes them particularly challenging to understand on a molecular level. A typical surfactant mixture for a shampoo might include up to 30 molecules with different chemistries. It’s both expensive and tedious to synthesize these molecules and develop new mixtures in the laboratory.
Using computers to predict the best combinations of surfactants for individual applications could be faster and cheaper. But building good models of individual molecules and their interactions with other components requires major computing power.
Researchers at Procter & Gamble are figuring investment in supercomputing will pay off in new products. They and collaborating researchers at Temple University are probing these questions with 6 million processor hours granted through the Department of Energy’s Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program.
The process of developing a new product begins with translating subjective data – such as how consumers rate the softness or whiteness of fabric – into physical or chemical tests that can be measured precisely. For example, the softness of a fabric can translate into a measure of its fibers’ strength. Whiteness can be quantified by imaging analysis.
Product developers then look for chemical mixtures that produce the desired properties but also are safe, sustainable and relatively inexpensive. Thirty surfactants can be mixed in thousands of closely related combinations, so it’s hard to find the best one, says Kelly Anderson of Procter & Gamble.
Results of the collaboration are starting to show up in the development pipeline at Procter & Gamble.
Finding new mixtures isn’t just about coming up with new combinations of previously synthesized surfactants. Scientists would like to incorporate new compounds, particularly those that could easily be derived from renewable resources.
The right set of computational methods could predict whether new compounds have the properties product developers want and also could help refine proposed structures. If a simulation indicates that changes could improve performance, chemists can test them in the lab to see if they’re feasible.
Overall, such methods could make laboratory work faster and greener, consuming fewer raw materials and producing less chemical waste.
Researchers are looking for models good enough to give reliable results. “This really is a grand challenge,” Anderson says. “You can’t test the chemicals because they haven’t been made. And you can only make a few of them. So which ones should you make?”
Some work in the lab will always be important, he adds. The idea is to eventually use computational methods for exploratory research and use laboratory experiments to confirm the results.
In many ways the work is analogous to the virtual crash tests engineers conduct. When researchers have a good understanding of the plastics or metals in cars, simulations accurately predict how those materials will perform in an accident. But scientists computationally understand these solid materials better than they understand the underlying physics of surfactant molecules in solution, Anderson notes. On top of fundamental research that must be done to enable predictions about properties of individual molecules, Procter & Gamble researchers also want to understand how these molecules interact with other components in the mixture.
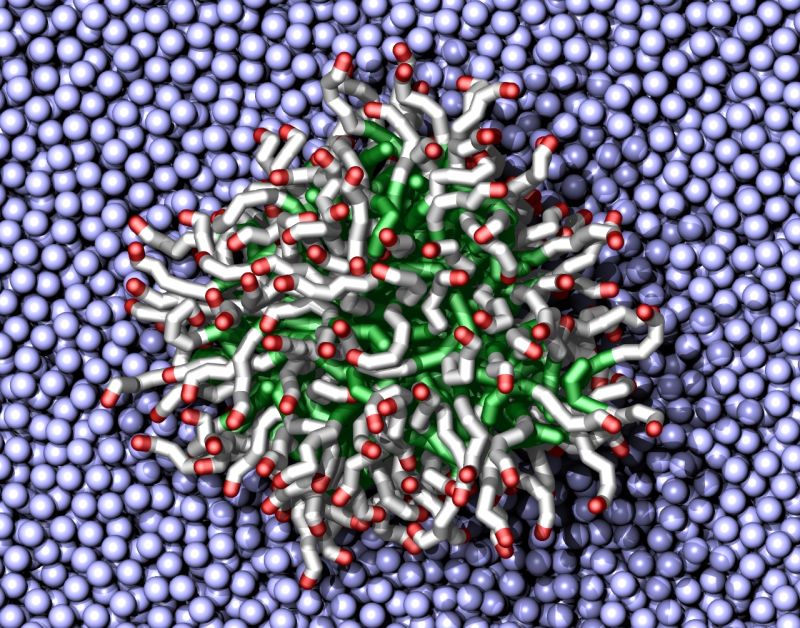
Surfactant molecules combine both oil-loving and water-loving characteristics. Understanding the behavior of just simple water remains a relatively intractable computational problem. Surfactant mixtures add molecules that have the greasy tails of oils, polar groups (with an uneven distribution of electrons) and even electronic charges. These chemical features have varying effects depending on both their environment and other features of the mixture. Such calculations quickly become extremely complicated.
There has been little precedent in academia for examining the kinds of complex mixtures that interest Procter & Gamble. Nonetheless, such systems are driven by molecular self-assembly, the same process that influences the ways proteins fold into compact, functional structures in living cells.
Although they thought self-assembly principles might help them analyze surfactant mixtures, in 2006 Anderson and his colleagues did not have the computing resources available to test their ideas. They started talking with Michael Klein, who recently moved from the University of Pennsylvania to Temple. His group had extracted useful information about complex molecular interactions using parallel computing and a great deal of effort and design.
Realizing that Klein’s group had the ability to help them with the basic research, Procter & Gamble forged a collaboration to help develop the fundamental parameters Anderson and his colleagues would use within the company. They received their first INCITE allotment in 2007, which gave them the resources to collaborate on developing a computational toolkit.
“The DOE INCITE program has allowed me and the academic collaborators to use the same computer,” Anderson says. “It’s made this collaboration work.”
INCITE gives researchers enough computer power to analyze a chemical mixture down to the single-atom level. However, in something with so many components, it’s also important to model a large sample to ensure the system is representative of all the possible chemistry. As a result, it’s generally impractical to look at them in such great detail.
Instead the Temple researchers typically use coarse-grained models that group three or four heavy atoms together as a single averaged site, says Russell DeVane, a research assistant professor at the Institute for Computational Molecular Science at Temple. Those models approximate physical properties of the surfactants’ chemical components, such as sulfonates and sulfates, sugar molecules, amine groups or long greasy tails.
As an approach, a coarse-grained model represents a tradeoff – like getting a photograph that covers a larger area, but is blurrier. So the idea is to run simulations that contain enough detail to accurately model the chemical interactions but also are efficient enough to encompass the necessary number of molecules.
Fundamental challenges remain, meanwhile, in understanding electrostatic interactions, DeVane says. The effective charge components of a mixture will experience depends on a number of factors, including the distance and the other components around the charge, such as water molecules or greasy portions of surfactants.
DeVane and his colleagues in the Klein group still are trying to understand some of those details. In addition, DeVane and his colleagues are trying to make the calculations more automatic, so the computer makes decisions that allow it to adjust parameters. With functions that vary in a linear way, this often isn’t difficult. But with more complex relationships, adjustments aren’t necessarily automatic.
These parameters from the Klein group provided information about single components and their interactions, which allowed Anderson to test prototype surfactant models on Intrepid, the IBM Blue Gene/P computer at Argonne National Laboratory near Chicago.
The initial data was compelling enough that Anderson convinced Procter & Gamble in 2008 to invest in computing resources he can use to test proprietary mixtures on-site. But he and his academic colleagues continue to use the Argonne computer to build and refine new models and new functional groups.
Results of the collaboration are starting to show up in the development pipeline at Procter & Gamble. The greatest project success to date is predicting the properties of various combinations of lauryl alkyl sulfate, whose structure includes three major components. Anderson has successfully predicted the properties of these slightly different structures in mixtures with other common surfactants, including alkyl benzene sulfonates and sulfated alkyl ethyoxylates.
Procter & Gamble researchers have developed promising new materials based on the computational results, Anderson adds. But a good chemical structure is only one piece of the puzzle. Because the company acquires many of its compounds through outside chemical suppliers, synthesizing a particular component molecule must make sense for the chemical supplier, both in terms of profits and their ability to meet demand.
Though a new product that directly results from these computational methods is still at least four years away, the approach is showing promise, Anderson says. “We’re already starting to deliver on the modeling program that began four years ago.”