J. Tinsley Oden of the University of Texas has a favorite quote from German science philosopher Hans Reichenbach: “If error is corrected whenever it is recognized as such, the path of error is the path of truth.”
“That’s sort of our mantra,” says Oden, director of UT’s Institute for Computational Engineering and Sciences. He and his research group are refining methods that estimate the error of mathematical models underlying computers simulations of physical systems, such as the molecular structure of materials. Knowing the error allows researchers to adapt the model to control error or change the model’s scales of time and space for more precision.
The ability to compute multiple scales is becoming more important as scientists investigate how the behavior of atoms and molecules affects the materials and processes they make up. Such understanding is vital to creating smaller, faster electronics, curing disease and addressing other problems.
However, “The development of models that function over many temporal and spatial scales is one of the most challenging aspects facing modern computation,” says Oden, who is an associate vice president for research and holds multiple appointments at Texas. “Virtually all the methods that have been proposed to transcend scale argue that the analyst has some insight and knows when a result is valid at one scale or needs information at another, “ Oden adds. “This very often is not the case.”
“Our hope is to bring some rigor to this process and let the analyst get an estimate of the error at each scale,” Oden says.
The Department of Energy’s Office of Advanced Scientific Computing Research is supporting Oden’s work to refine algorithms – mathematical recipes computers use – that represent physical processes at multiple scales. Oden works with a team of mathematicians, chemists, chemical engineers and others to incorporate error estimation into mathematical models, then adapt the models to minimize that error.
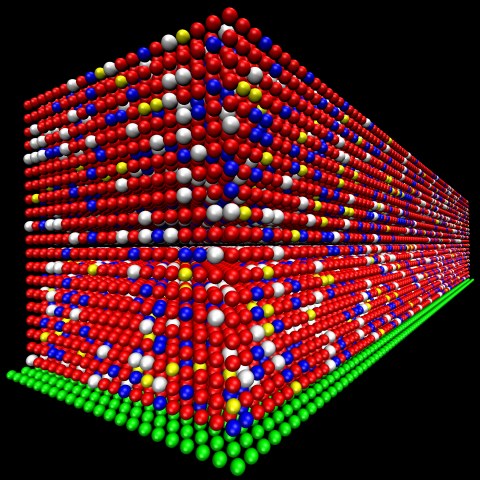
This is a visualization showing the distribution of particles in the lattice generated by the polymerization algorithm developed by Texas Professor C. Grant Willson’s group. In this 20×100×20 polymer lattice, red particles denote monomer molecules, blue are cross-linkers, yellow are initiators, white are voids and green particles represent substrate molecule.
The process, called adaptive modeling, is based on what Oden called a revelation: That techniques used to estimate error in models at the scale of atoms or molecules can apply to larger scales, too.
The researchers start with a base model – a mathematical model of a system at the atomistic or molecular level. The nature and number of elements at this minuscule level make the model “so complex and intractable that you don’t have a hope of solving it. You don’t want to solve it,” Oden says, but the base model is a way to judge other, coarser models set at larger scales. Unlike the base, these “surrogate” models can be solved, Oden says.
“The beautiful thing is when we solve it we can estimate the error,” he adds. “If we’re not happy with the error, we need a technique to refine the surrogate and make it more sophisticated.”
That’s the other part of Oden’s research: Goal-oriented error estimation. When researchers run computer models of physical systems, they typically choose just a few things they want to know about most. Oden’s group wants to focus error estimation on those areas so researchers can judge the reliability of the results.
“To be able to estimate the error puts the analyst in an extremely strong position,” Oden says. Researchers can determine if the model violated any important principles. They can decide whether the error level is acceptable, or if the problem should be examined at a different scale for a more precise answer.

This shows the 20×100×20 polymer lattice after “shrinkage” due to the formation of covalent bonds during polymerization. Notice the curves at both the end and the top surface.
Oden is testing the adaptive modeling code by modeling a semiconductor production method developed by Texas engineering professor C. Grant Willson. The process pushes a quartz template into material on a silicon chip. Ultraviolet light shines through the template, converting the material to a polymer and making it denser in places. The imprint creates the chip’s electronic circuitry.
Oden’s model simulates the polymerization and densification process at the molecular level. “We’re looking at how you simulate events that take place on a macroscale – the scale of manufacturing the device – that result from activities that occur at the molecular scale – nanoscale and smaller,” he adds. The simulation could help optimize the manufacturing process.
Semiconductors are only the first of what could be a long line of applications for the adaptive modeling code, Oden says. “We can look at many, many different chemical constituencies and add different features to the model. This is just the building block for more sophisticated models,” he adds.
The code runs on computer clusters of about 50 processors, Oden says, but has been projected to run well on systems of up to 100 processors. The plan is to try it on Lonestar, the University of Texas supercomputer with a top speed of 55 trillion calculations per second.
“We’ll take it to the limit within a year,” Oden adds.